Word2Vec 논문 정리해보기
CS224n을 듣기 시작하고 나서 같이 나오는 suggested readings를 가끔 읽는데, word2vec의 논문으로 유명한 Efficient Estimation of Word Representation in Vector Space도 그 중 하나이다. 공부를 하면서 다시 볼만한 내용, 생각났던 내용들을 적어두기 위해 이 포스트를 작성했다.
word2vec
word2vec는 word embedding 방법 중의 하나로, 논문에 제안한 모델에 대한 간략 설명으로 “for computing continous vector representations fof words from very large data”라고 적혀있다.
처음으로 NLP 쪽으로 공부를 하는 거라 어렵기도 하고 재밌기도한 개념이 많이 나왔다. 그래도 CS231n의 강의 몇개를 찾아보고 정리했었는데, 그 이후에 보니까 나름 그럭저럭 이해할만한 논문이었던 것 같다. CS224n 교수님이 설명 잘 하신 것도 있겠지만..?
여튼 다시 볼만한 내용만 작성하고, conclusion같은 것들은 빼고 작성한다.
Introduction
2013에 나온 논문인데, 그 때의 많은 NLP 방법들은 단어를 하나의 작은 단위로 취급하고 있었다고 한다. 근데 이런 방법은 단어 사이의 유사도를 판별하기가 힘들다. 그리고 성능이 데이터의 크기에 크게 좌우된다. 하지만 어느정도 장점도 가지고 있는데, 간단하고 robust하며, 나름 좋은 성능을 냈다고 한다. Ngram이 그 중 하나라고 한다. 1 하지만 통계적인 방법을 이용하지 않고 기계학습을 사용한 방법을 이용하면서 distributed representation을 사용하는 방법이 꽤 좋은 접근법으로 떠올랐다고 한다. 2
그래서 50 ~ 100정도 dimension에 word vector로 임베딩 하는 것을 소개한다. 그러면서 word vector의 놀라운 점을 소개한다. word2vec을 설명하다 보면 많이 나오는 단어를 더하고 빼는 연산을 아래처럼 예시를 보여주면서 소개한다.
vector(”King”) - vector(”Man”) + vec- tor(”Woman”) results in a vector that is closest to the vector representation of the word Queen
단어를 연속적인 벡터로 표현하는 것이 이 논문이 처음은 아니다. 하지만 해당 방식을 제안했던 많은 논문들 중 NNLM에 관한 논문2에서 제안한 방식이 많은 주목을 받았다. feedforward neural network 방식을 사용한다고 한다.
Model Architecture
neural network를 사용해서 distributed representation을 구현한다. 해당 아키텍쳐를 말하기 전에 computational complexity를 먼저 논한다고 한다. 모델을 소개하면서 어떻게 정확도는 높이고 complexity는 낮추었는지 소개해준다. 일단 앞으로 나올 모델들은 이런 training complexity를 갖는다고 한다.
\[O = E \times T \times Q\]\(E\)가 training epoch, \(T\)가 training set에 존재하는 단어의 수, \(Q\)는 앞으로 각 모델에서 정의될 것이라고 한다. 보통 epoch는 3 ~ 50으로 정하고, \(T\)는 1 billion까지로 정한다고 한다. 학습은 SGD와 backprop을 이용한다고.
NNLM
NNLM은 input, projection, hidden, output layer로 구성이 되어 있다. input layer에서 \(V\)가 단어의 수라고 하면, 1-of-\(V\) coding(one hot)을 사용해서 단어를 인코딩하고, 공유되는 projection용 행렬을 사용해서 \(N \times D\) 차원의 projection layer로 project한다고 한다. \(N \times D\) 차원이니까 한번에 \(N\)개의 단어를 사용가능하다. 보통 \(N\)은 10정도로 쓰고, projection layer는 500 ~ 2000 차원쯤 쓴다고 한다. hiddden layer는 500 ~ 1000차원쯤, output layer에 대해서는 \(V\)라고만 나와있다. 자 이렇게 되니까 파라미터 수는 아래와 같다.
\[Q = N \times D + N \times D \times H + H \times V\]\(H \times V\)가 매우 비싼 연산이므로 hierarchical softmax를 사용한다고 한다. (이건 다음에 정리해야지) 또는 normalize를 안한다고. 어쩄든 그런 방법을 적용하면 \(log_2 V\) 정도로 줄어들어서 \(N \times D \times H\)가 제일 complexity해진다.
word2vec에서는 huffman binary tree를 사용하는데, 이는 \(V\)를 \(log_2(Unigram\_perplexity(V))\)정도로 줄여준다고 한다. 이렇게 적어두고.. 사실은 \(V\)는 bottleneck이 아니니 그렇게까지 중요하진 않다고 한다.
RNNLM
RNN의 활용이 Feedforward NNLM의 한계(context length를 명시한다던가)를 극복하기 위해 제안되었다. 그 결과 이론적으로 일반 NN보다 복잡한 패턴에 대해 훨씬 효율적인 표현이 가능했다.
New Log-linear Models
이전 Model Architecture에서 소개했던 것들은 neural net이 매력적임을 알게 해주었지만, 대부분의 복잡성은 non-linear hiddne layer에서 오는 것을 알 수 있었다. (\(N \times D \times H\)) 그래서 새로운 모델에서는 NNLM을 두 단계로 나누어서 학습을 한다고 한다. 우선 continous word vector를 간단한 모델로 학습시킨 다음에 N-gram NNLM을 그 위에서 학습시킨다.
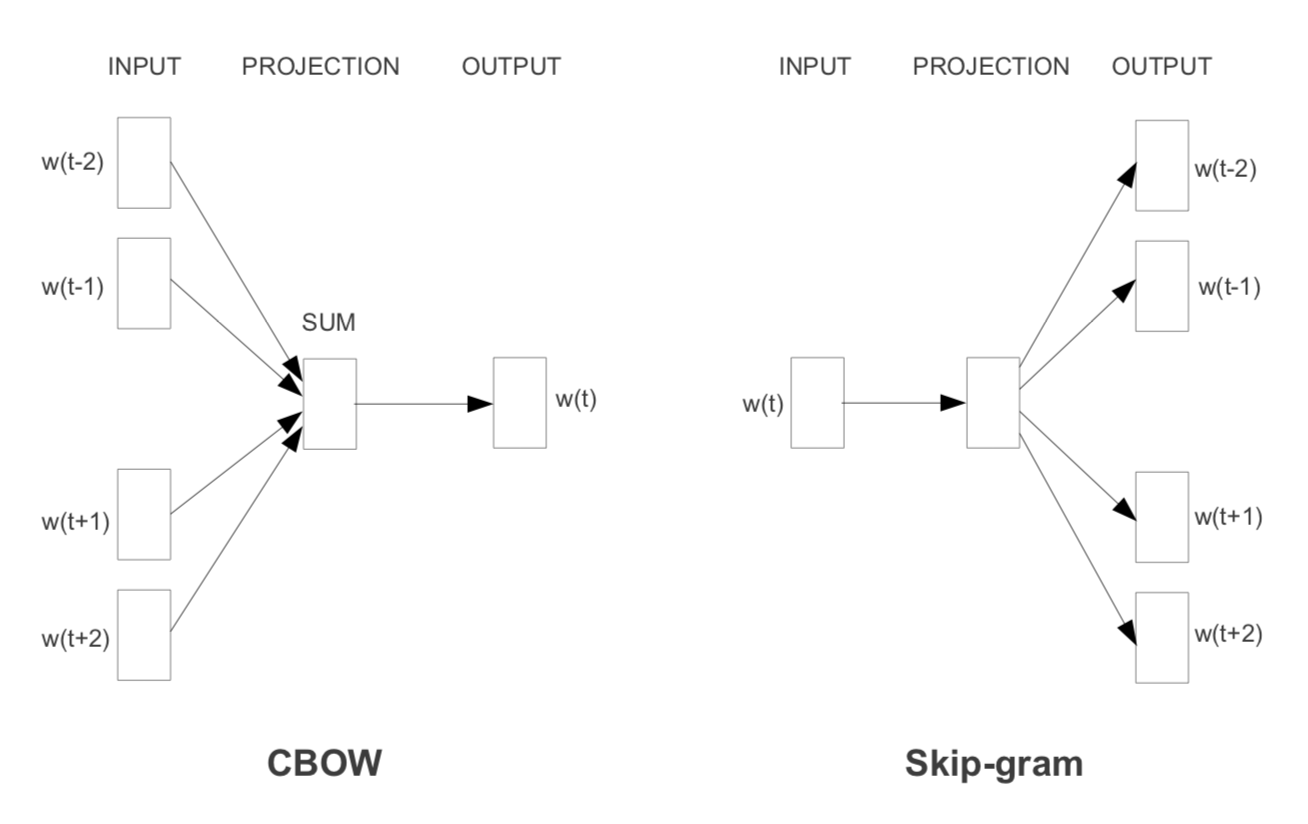
Continuous Bag of words model
그래서 이 논문에서 제안한 아키텍쳐 중 하나가 feedforward NNLM과 비슷하지만, non-linear hidden layer를 없애고, projection matrix 뿐만 아닌 layer까지 모든 단어들이 공유하게 한 모델이다. 그래서 모든 단어가 똑같이 project된다. 그리고 이를 설명하면서 아래처럼 설명을 하는데,
Furthermore, we also use words from the future
이는 아마 Ngram과 다르게 단어의 앞 뿐만 아니라 뒤에 있는 단어들도 참고한다는 말인 것 같다. 그래서 complexity는 아래와 같아진다.
\[Q = N \times D + D \times log_2 (V)\]앞 뒤로 4개의 단어를 가져오도록 window size를 결정했을 때 가장 좋은 성능이었다고 한다.
Continuous skip-gram mdoel
두번째 아키텍쳐는 CBOW와 유사한데, 한 단어로 같은 문장안의 주위의 단어를 classification을 maximize하는 모델이다. training complexity는 아래와 같다. \(C\)가 maximum distance of the words라고 하는데, window size와 비슷한 의미로 받아들이면 될 것 같다.
\[Q = C \times ( D + D \times log_2 V )\]뭐 이렇게 말하는 것보다 쉽게 말하면 CBOW는 현재 단어를 주위 단어(context)를 기반으로 예측하고, Skip-Gram은 현재 단어로 주위 단어(context)를 예측한다.
-
T. Brants et al. 2007 Ngram의 논문으로 통계적인 방법론을 사용했다고 한다. ↩
-
A Neural Probabilistic Language Model word2vec의 NNLM에 관한 논문으로, distributed representation을 설명하며 참고로 달려있는 논문 중 하나이다. ↩ ↩2