TinyBERT: Distilling BERT For Natual Language Understanding 리뷰
TinyBERT는 Under Review 상태인 논문이고, 화웨이 Noah’s Ark Lab에서 나온 논문이다. 코드는 GitHub huawei-noah/Pretrained-Language-Model/TinyBERT에 있다. arxiv 링크는 https://arxiv.org/abs/1909.10351이다.
추론 가속화와 model size 압축을 위해 KD를 적용한 논문으로 teacher BERT 모델에서 stduent BERT 모델으로 Distillation을 시도하는 논문이다. 96% 이상의 성능을 보존함과 동시에, 7.5x 작고 추론이 9.4x 빠른 모델이다.
1 Introduction
- 보통 Compression은 quantization, pruning, knowledge distillation 등을 시도
- 그 중에서도 KD에 집중한 논문이며, loss를 어떻게 디자인하느냐에 신경을 많이 썼다고 함
- 아래 representations을 loss를 구하기 위해 이용
- output of embedding layer
- hidden states and attention matrices
- logit output of prediction layer
- main contributions
- transformer distillation 방식을 새롭게 제안
- two-stage distillation 방식을 사용
- teacher model의 96%의 성능을 보존
2 Preliminaries
Background라 패스
3 Method
3.1 Transformer Distillation
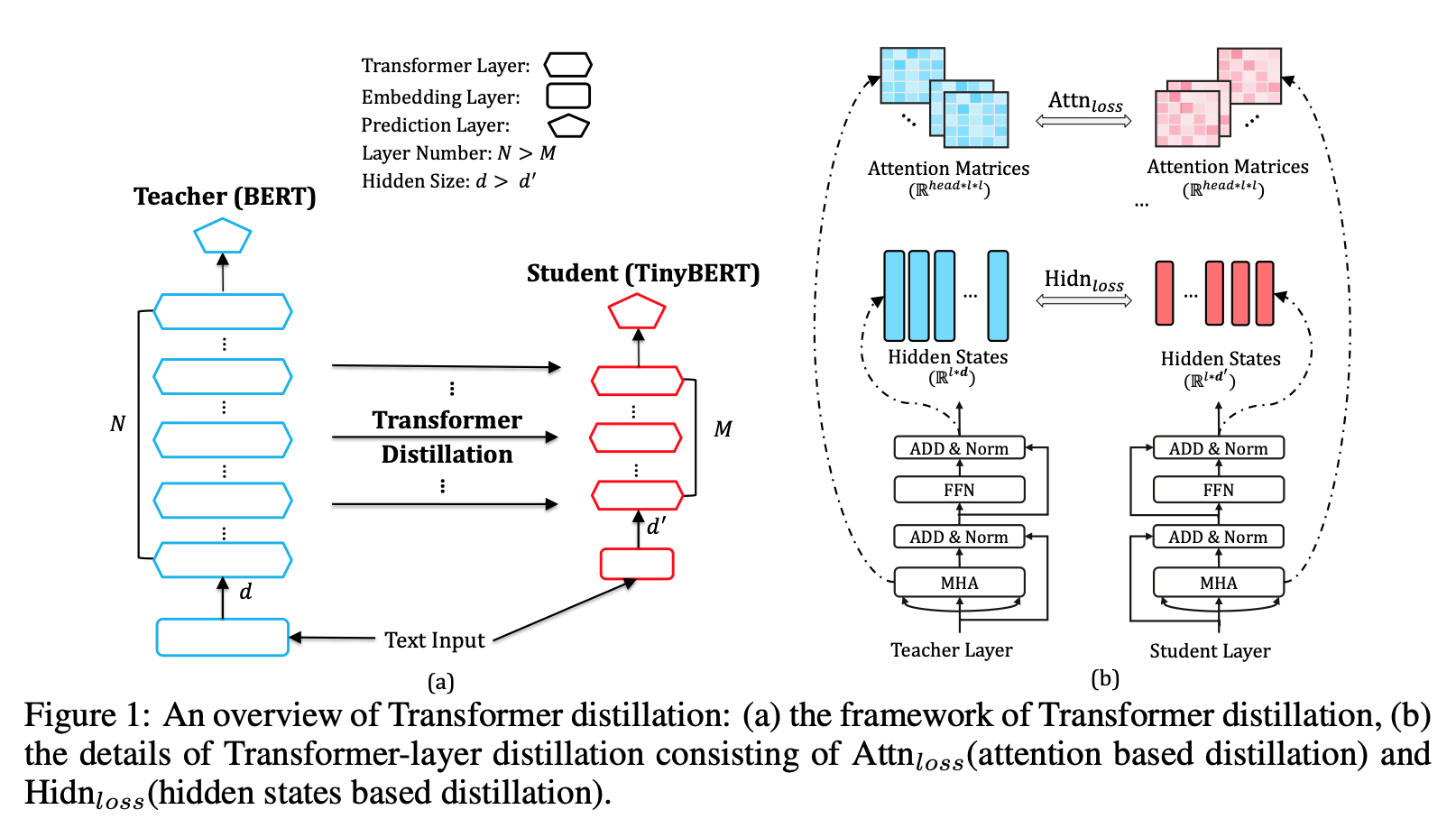
Problem Formulation
- Teacher가 N개의 Transformer Layer
- Student가 M개의 Transformer Layer
- embedding layer의 output은 layer 0으로 간주
-
Distillation은 아래식을 최소화하는 방향으로 간다.
\[l_{model} = \sum^{M+ 1}_{m = 0} \lambda_{m}l_{layer}(S_m, T_{g(m)})\]
Transformer-layer distillation
-
Loss for attention mechanism
\[l_{attn} = \frac 1 h sum^h_{i = 1} \text{MSE}(\textbf A_i^S, \textbf A_i^T )\] - 특이한 점은 softmax를 타기 전의 matrix를 loss function의 input으로 넣는 것인데, 이게 수렴이 더 빠르게 되었다고 한다.
- 이 점에 대해서 의견을 붙이자면, softmax를 타고 나면 낮은 attention 값들에 대한 정보가 많이 손실되는 편이라 그렇지 않나 싶다.
-
Loss for hidden states
\[l_{hidn} = \text{MSE} (\textbf{H} ^S \cdot \textbf W_h, \textbf{H}^T)\] - \(\textbf W_h\)는 learnable linear transformation이다. tinyBERT에서는 hidden size도 줄이고 싶기 떄문에 사용하는 값이다.
Embedding Layer Distillation
-
Loss for embedding layer
\[l_{embd} = \text{MSE} (\textbf{E} ^S \cdot \textbf W_e, \textbf{E}^T)\]
Prediction Layer Distillation
-
Loss for Prediction Layer
\[l_{pred} = -\text{softmax}(z^T) \cdot \text{log_softmax}(\frac {Z^S} t)\] -
prediction layer에서는 student model의 logit에 패널티를 주었지만, 실제 실험에서는 t = 1이 제일 좋았다고 한다.
3.1 TinyBERT Learning

- general-distillation과 task specific distillation을 시도해봄
- general distillation은 fine-tuning하지 않은 원 Bert 모델에 대해서 Prediction Layer Distillation을 제외하고 진행하는 Stage이다.
- task specific istillation은 data augmentation을 적용하여 distillation을 수행한다. data augmentation의 상세한 절차는 논문 Appendix A에 있다.
4 Experiments
- tiny bert model을 M=4, d=312, intermeidate_size=1200, h=12로 잡아서 진행했다.
4.2 Experimental Results on GLUE
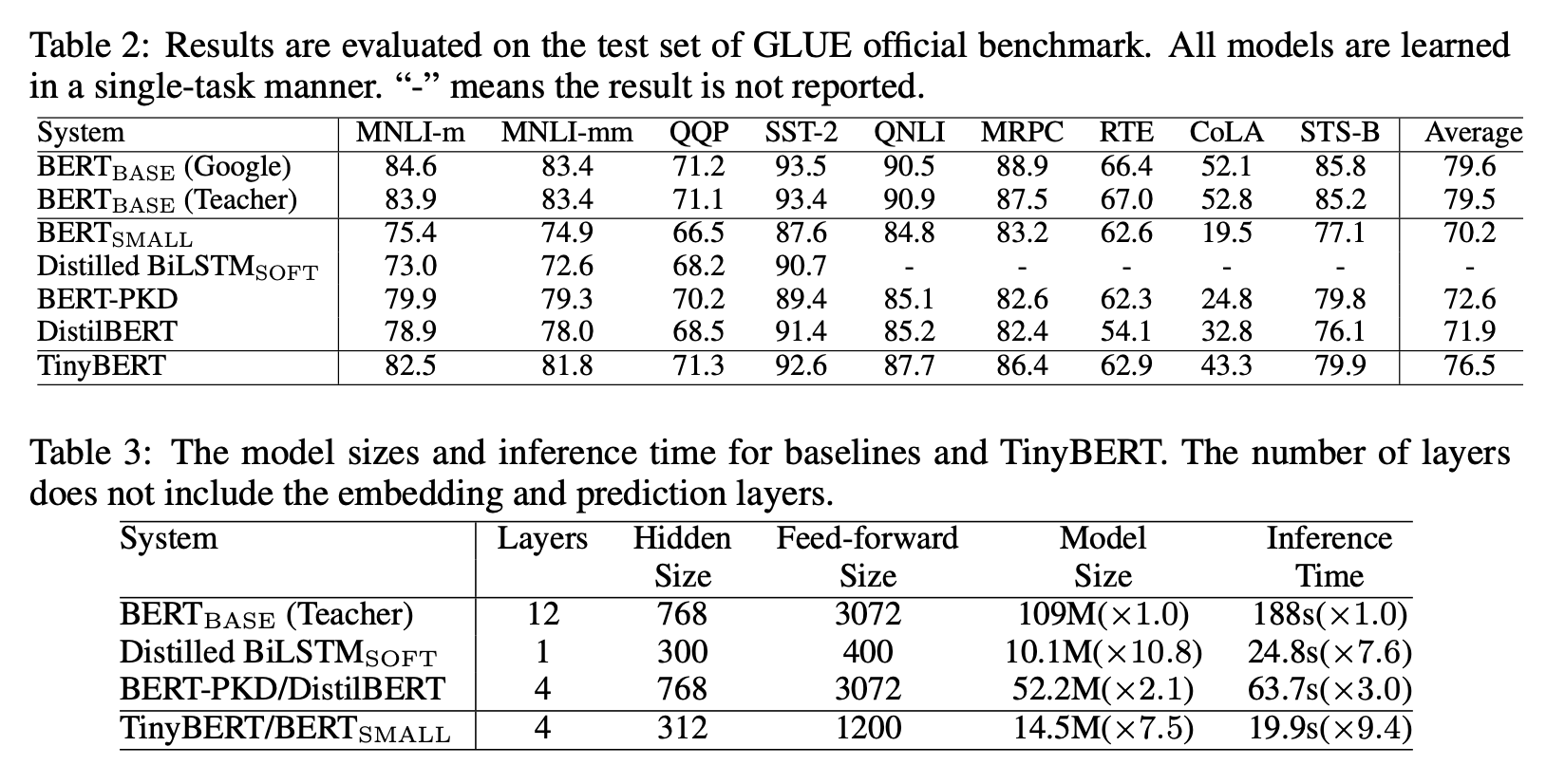
- 일단 BERT small 보다는 훨씬 잘함
- 기존 KD보다도 잘함
- 하지만 CoLA와 같은 태스크는 많이 어려움..
4.3 Effects of Model Size
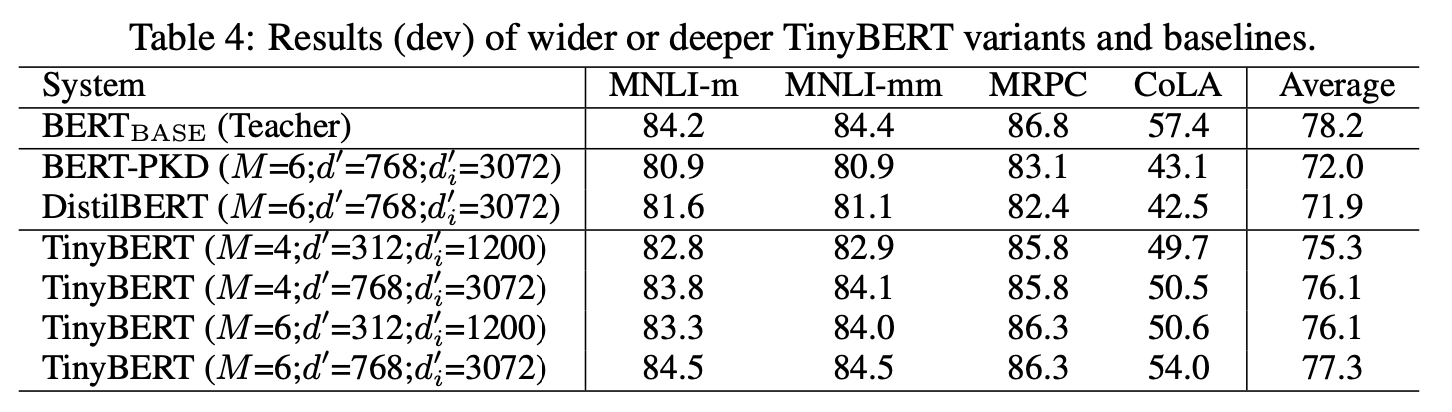
- 그래도 더 큰 모델이 잘한다는 같다
- 그래도 4layer가 6layer보다 더 잘할 수 있다는 것은 놀라운 점
4.4 Ablation Studies

왜 4개 태스크에만 했지…?
- DA=Data Augmentation, TD=Task-specific Distillation, GD=General Distillation
- 그래도 일단 4개의 태스크에서 볼 수 있는 점은 생각보다 DA가 영향이 크고, TD는 당연히 영향이 크다.
4.5 Effect of Mapping Function
- Mapping Function = tinyBERT hidden layer loss먹일 때 어떤 레이어를 어떤 레이어와 loss 계산할 지
- uniform strategy가 꽤 큰 격차로 이긴다.
5 Conclusion
- Large 모델들에 대해서도 해보고 싶다
- joint learning of distillation, quantization/pruning도 다른 방법이 될 수 있다.
squad가 안되어 있길래 찾아보니 Appendix에 있다. 꽤 잘된 것 같은데 왜 안넣어놓았을까??

May 1, 2020
Tags:
paper