TensorFlow의 SparseCategoricalCrossentropy의 from_logits 옵션
최근 모델 학습을 진행하면서 필요 이상으로 메모리를 많이 먹는 느낌이 있어 프로파일링을 해보았다. TensorBoard profile 기능의 memory_profile을 보다보니 SparseCategoricalCrossentropy와 softmax가 굉장히 많은 메모리를 먹고 있었다.
tensorflow 2.4.1 기준으로 작성했습니다.
SparseCategoricalCrossentropy의 from_logits 옵션 뜯어보기
예전에 from_logits=True를 사용할 때는 이런 느낌이 없었던 것 같아서 from_logits 옵션부터 보았다.
TensorFlow 문서(https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy)를 보다보면 from_logits 옵션을 아래처럼만 설명한다.
Note - Using from_logits=True may be more numerically stable.
왜 numerically stable한지 한번 살펴보자.
현재 master의 sparse categorical crossentropy 코드를 타고타고 들어가다보니 https://github.com/tensorflow/tensorflow/blob/85c8b2a817f95a3e979ecd1ed95bff1dc1335cff/tensorflow/python/keras/backend.py#L4867 여기에 들어왔는데, 아래와 같은 로직을 탄다.
def sparse_categorical_crossentropy(target, output, from_logits=False, axis=-1):
"""
...
"""
...
# Use logits whenever they are available. `softmax` and `sigmoid`
# activations cache logits on the `output` Tensor.
if hasattr(output, '_keras_logits'):
output = output._keras_logits # pylint: disable=protected-access
from_logits = True
elif (not from_logits and
not isinstance(output, (ops.EagerTensor, variables_module.Variable)) and
output.op.type == 'Softmax') and not hasattr(output, '_keras_history'):
# When softmax activation function is used for output operation, we
# use logits from the softmax function directly to compute loss in order
# to prevent collapsing zero when training.
# See b/117284466
assert len(output.op.inputs) == 1
output = output.op.inputs[0]
from_logits = True
elif not from_logits:
epsilon_ = _constant_to_tensor(epsilon(), output.dtype.base_dtype)
output = clip_ops.clip_by_value(output, epsilon_, 1 - epsilon_)
output = math_ops.log(output)
...
위 코드를 설명하면 아래와 같다.
from_logits=True라면 값을 그대로 loss의 입력으로 넣는다.from_logits=False라면_keras_logits이 존재하면 (sigmoid나 softmax의 결과값이라면) 입력값을 다시 받아와서 loss의 입력으로 넣는다.- 이전 Op이 Softmax라면, 입력값을 다시 받아와서 loss의 입력으로 넣는다.
- 아무것도 해당되지 않는다면
log함수를 취해서 loss의 입력으로 넣는다.
정리하면
내 생각으로는 from_logits=True라면 log_softmax를 취하고, 나머지는 log만 취해서 연산할 줄 알았는데, 그것이 아니라 from_logits=True 일 때 값을 그대로 사용한다.
그래서 오히려 from_logits=False를 사용하면서 모델 출력값에 softmax를 취하면 메모리를 더 먹게 된다. (softmax가 속도가 그렇게까지 느리진 않으니 속도는 제쳐두자)
진짜인지 확신이 안서서 Tensorboard Graph를 그려보았다.
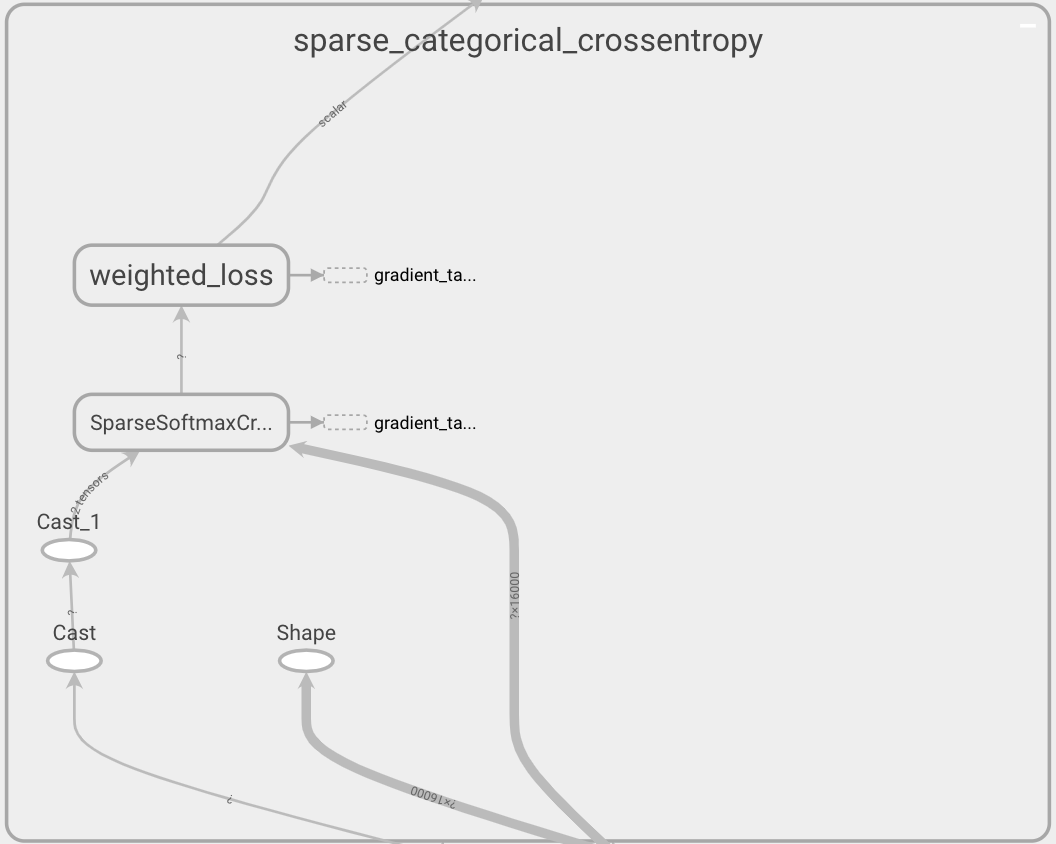
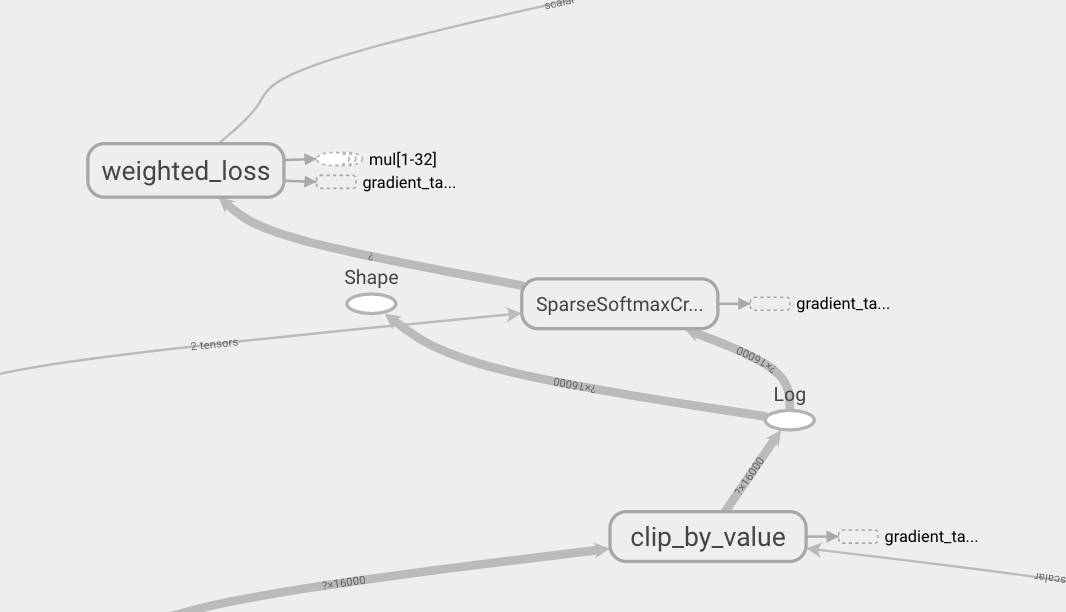
확실히 prob을 넘길 때 위의 코드 스니펫과 같이 clip_by_value + log 노드가 생성되는 것을 볼 수 있다.
그에 비해 logit을 넘길 때에는 중간에 아무런 노드가 생성되지 않는다.
softmax 결과값, log 결과값이 메모리를 더 먹으니 메모리가 훨씬 아껴진다고 볼 수 있다.
특히 sequence labeling 같은 경우에는 [batch, timestep, num_classes]의 shape를 가지니 메모리 절약의 체감이 훨씬 클 것이다.
아마 numerically stable하다는 것의 이유는 log softmax를 여러번 취하냐 한번만 취하냐의 차이로 보인다.
근데 진짜 같은 식인가
log softmax는 여러번 연산해도 똑같은 값을 가지기 떄문에 아마도 커널 단에서 log softmax를 한번 더 할 것 같다.
코드 타고타고 들어가보니 실제로 더 한다.
그럼 진짜 softmax 사용하고 from_logits=False 사용하는 것은 불필요한 연산 + 메모리 낭비이지 않을까?
위 코드를 보니 아예 sparse softmax crossentropy with logits 입력을 unnormalized log prob으로 보는 듯 하다.
참고
- https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy
- https://github.com/tensorflow/tensorflow/blob/85c8b2a817f95a3e979ecd1ed95bff1dc1335cff/tensorflow/python/keras/backend.py#L4867
- https://github.com/tensorflow/tensorflow/blob/85c8b2a817f95a3e979ecd1ed95bff1dc1335cff/tensorflow/python/ops/nn_ops.py#L4067
- https://github.com/tensorflow/tensorflow/blob/dec8e0b11f4f87693b67e125e67dfbc68d26c205/tensorflow/core/kernels/sparse_xent_op.h#L172
의식의 흐름대로 작성했지만 일단은 이런 이유로 당분간은 classifier 작성할 때 from_logits=False + softmax는 쓰지말자.