On Layer Normalization in the Transformer Architecture 리뷰
ICML 2020에 나온 논문이고, ZeRO 학습 튜토리얼에 쓰인 PreLN 구조를 소개한 논문이다. Microsoft Research에서 나온 논문인듯…? 그래서 ZeRO 튜토리얼에서 쓴 것 같다. BERT 학습 도중 읽어본 논문이라 간단하게만 정리
Abstract
- learning rate warm-up이 필요한 이유를 살펴보고 LN(LayerNormalization) 컴포넌트의 위치가 왜 중요한지도 살펴봄
- PostLN(기존 Transformer Block) 구조는 초기에 output layer 근처의 gradient의 기댓값이 매우 크다.
- 그래서 warmup이 필수적이고, 없을때는 학습이 엄청 unstable하다.
- 근데 여기서 제시한 PreLN 구조는 초기에도 괜찮다.
Introduction
- Transformer Block의 표현력이 매우 풍부하기 때문에 학습만 잘 되면 좋은 성능이 나오지만, 실제로 학습을 시켜보면 LR에 매우 민감하다는 것을 알 수 있다.
- 이는 이 논문에서 말하길 초기 Gradient가 매우 불안정하기 때문이라고 한다.
- 그래서 CNN이나 다른 Seq2Seq 모델들보다 optimize하기 너무 어렵다.
- 그래서 나온 것이 warmup stage인데, 이렇게 학습을 하면 학습도 늦어지고 추가적인 하이퍼 파라미터 튜닝도 많이 필요하다.
- 이 문제를 해결하기 위해 mean field theory를 이용함
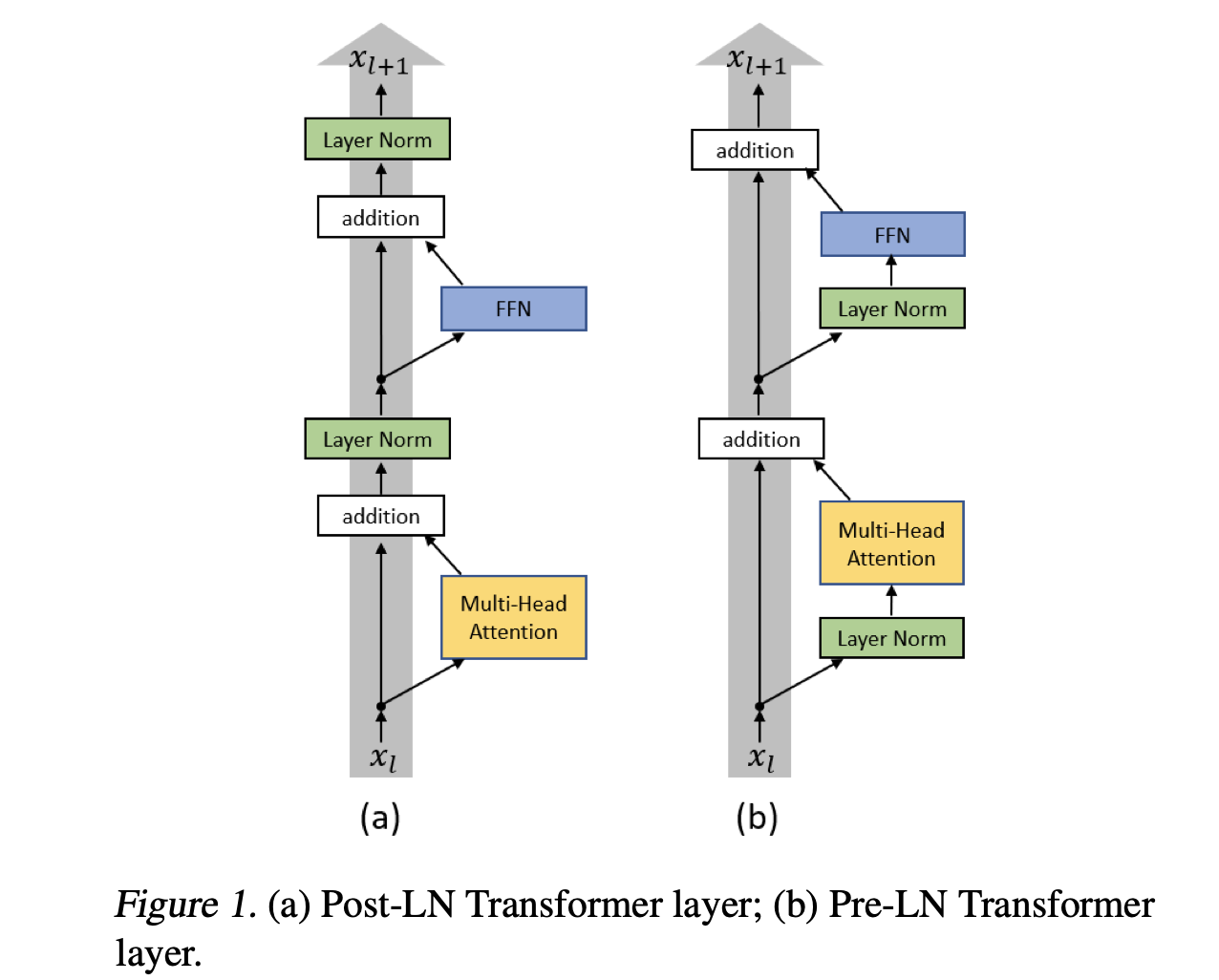
- LN 위치를 바꾸어보았고
- gradient가 훨씬 잘 분배되면서
- LN이 gradient control에 많은 역할을 하는 것을 보여주었다.
- 결론적으로 PreLN 모델이 학습도 빠르면서 적은 스텝만으로 비슷한 성능을 낼 수 있다.
Related Works
패스
Optimization for the Transformer
Transformer with Post Layer Normalization
- 이건 추후에 나오는 표기 때문에..
- \(W^1\), \(b^1\) -> intermediate dense layer. base 기준으로 768 -> 3072 가는 그 레이어
- \(W^2\), \(b^2\) -> intermediate output layer. 3072 -> 768 가는 그 레이어
The learning rate warm-up stage
- warmup때는 LR max까지 linear하게 증가
- PostLN 구조에 얼마나 치명적인지 보기 위해서 (Popel & Bojar, 2018) IWSLT14 German-to-English 번역 태스크를 풀어봄

- 결과
- 결국 Adam을 쓰나 SGD를 쓰나 WarmUp이 중요한 것은 마찬가지로 보인다.
- 또한 warmup step 수에 굉장히 민감한 것으로 보인다.
- 이와 관련해서 논문에 레퍼런스로 달려있진 않지만, LAMB Optimizer 논문도 많은 도움이 되었다.
Understanding the Transformer at initialization
Notation, Initialization과 관련해서는 자세히 설명이 되어있지만 패스
Post-LN Transformer vs Pre-LN Transformer
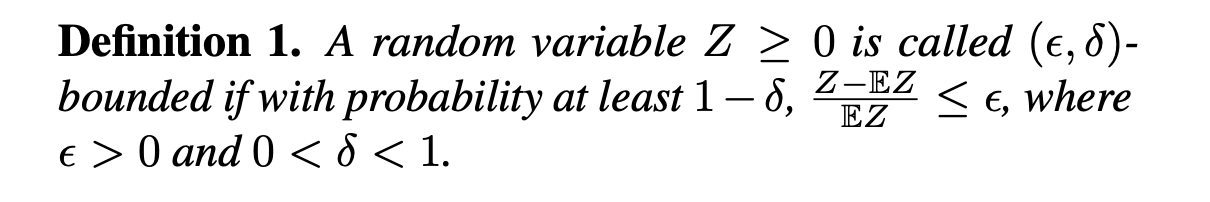
- 어찌되었든 \(Z\)가 epsilon delta bounded면 높은 확률로 기댓값에서 먼 위치에 있지 않다는 것을 알 수 있다.
- 그래서 위를 생각하고 아래 Theorem을 보자

- 봐야하는 건 sqrt안에 L로 나누는 항이 있는 것.
- Gradient의 Frobenius Norm이 훨씬 작다.
- PostLN은 Layer 개수에 상관없이 \(O(d\sqrt {\ln d})\)인데 PreLN은 레이어가 많아질 수록 마지막 레이어에 걸리는 Gradient가 줄어든다.
- 위 theorem을 이해하기 위해서 lemma 3개가 나오는데 이를 정리해보면
- d-dimensional Gaussian vector를 ReLU에 넣었을 때 그 결과의 l2 norm의 기댓값 -> 그냥 기본적으로 뒤 증명에서 활용하기 위함
- Pre/Post LN Layer의 중간 결과/최종 결과.
- PostLN은 레이어가 달라져도 Scale이 크게 달라지지 않는데
- PreLN은 레이어가 증가함에 따라 Scale도 같이 커진다.
- LayerNormlization에 실리는 Gradient가 input vector의 norm에 반비례한다.
- 따라서 메인 아이디어는 “LayerNorm이 Gradient를 Normalize한다.“가 된다.
- PostLN 구조는 스케일이 일정하기 때문에 Last Layer의 Gradient도 일정한데 비해 PreLN은 스케일이 레이어 수에 비례하기 떄문에 Gradient는 \(\sqrt L\)로 Normalize된다.
Empirical verification of the theory and discussion
각 레이어 Gradient의 Frobenius Norm을 기록한 결과
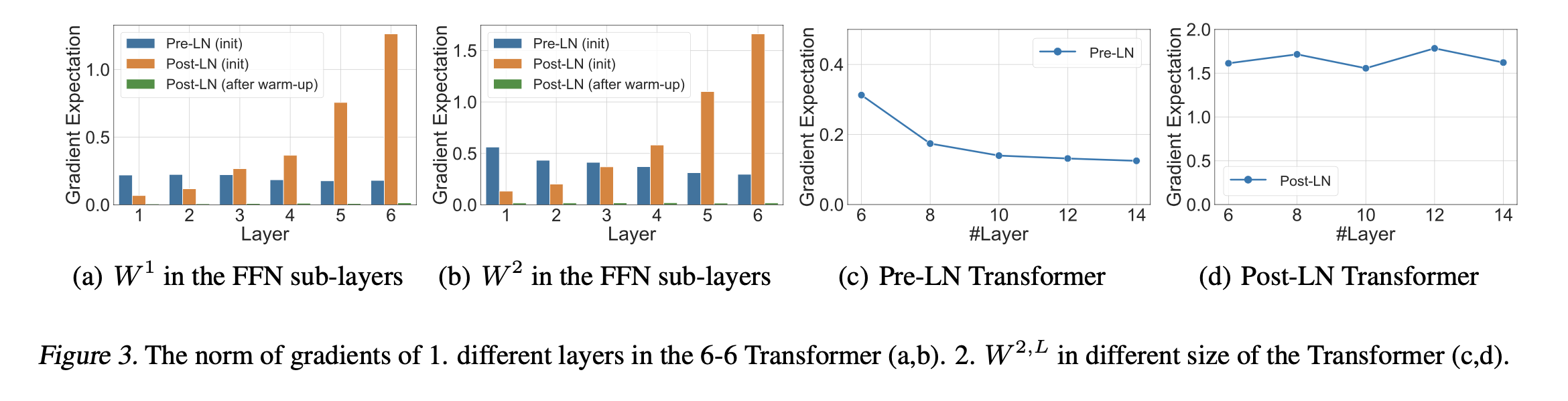
여기서 PreLN이 더 학습이 잘 될 수 있을 것을 알 수 있는데, PostLN의 경우에는 Gradient가 너무 크게 실려서, LR을 작게 주거나 Warmup Stage를 주어야 한다. 하지만, PreLN 구조는 LR 조정만으로 잘 학습이 가능할 것이다.
Experiment
NMT랑 BERT했지만, 관심있는 것은 역시 BERT.
BERT와 비슷한 사이즈의 Corpus를 가져갔을 때 월등한 결과를 보였다.
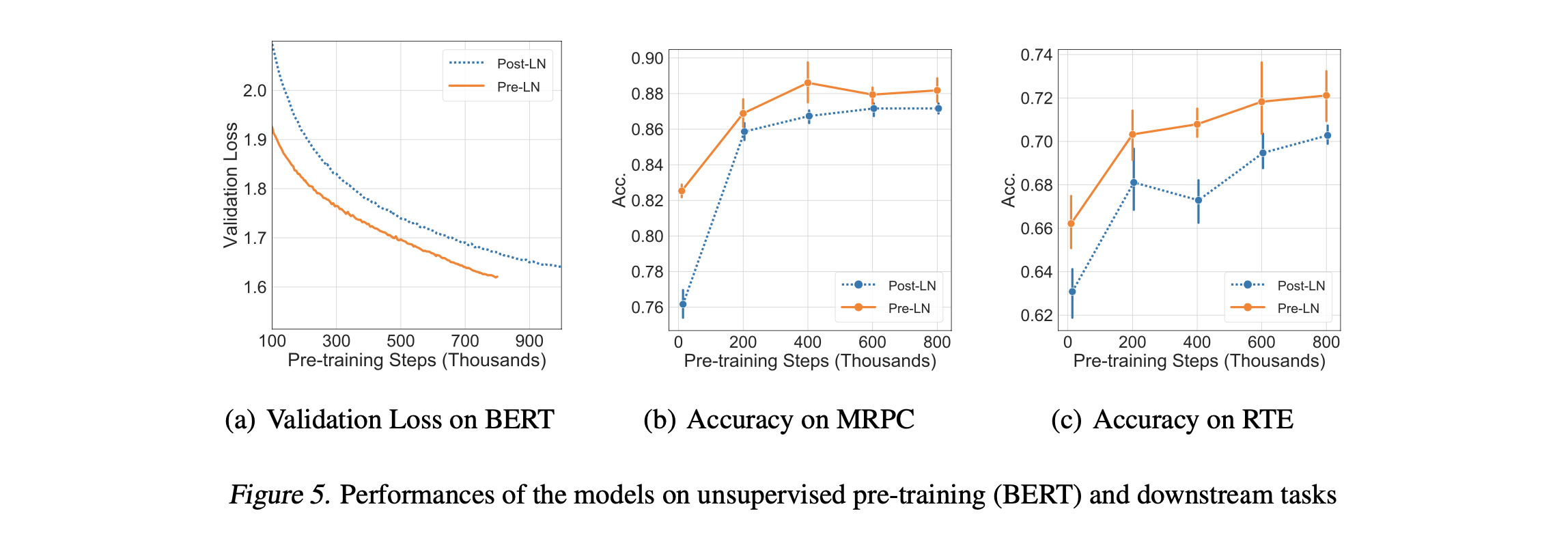
validation loss가 1.7 근처에 도달하는데 Warmup 10k를 준 PostLN 모델은 700k Step을 밟았고, PreLN모델은 500k만 학습을 진행했다고 한다.
Conclusion
결국 뭐 PreLN이 잘된다.. Warmup Stage는 안전하게 없앨 수 있다.. 정도로 요약이 가능한데, 여기서 말하는 것으로 보아 이전에 본 BERT 분석 논문들의 Task Specific weight들이 조금 잘못 분석된 논문들인가?? 싶다.
자세한 증명은 논문 Appendix에 존재한다.
July 16, 2020
Tags:
paper