형태소 분석기와 Branching entropy를 활용한 비지도 신조어 탐색
형태소 분석기를 사용하면서 겪는 가장 까다로운 문제 중 하나는 새로운 단어에 대한 대응일 것이다. 신조어를 대응하지 않자니 사용하는 컴포넌트의 성능이 떨어지게 되고, 일일히 대응하자니 찾아서 추가하기에 매우 많은 리소스가 든다. 이 때 어떻게 해볼 수 있을까 고민을 하다가 통계적인 방법을 활용해 자동으로 신조어를 찾는 방법을 확인해보았다.
많은 부분을 lovit님의 글을 시작으로 찾아볼 수 있었기에 많은 감사를 표하고 싶다.
Branching entropy
나의 상황에 가장 사용하기 좋아보이는 방법으로 보였다. 간략히 설명하면 “특정 상황(앞서 등장한 문자열)에서 다음에 등장할 문자열들의 확률의 엔트로피가 높다면 단어의 경계일 확률이 높다”정도로 이해할 수 있다.
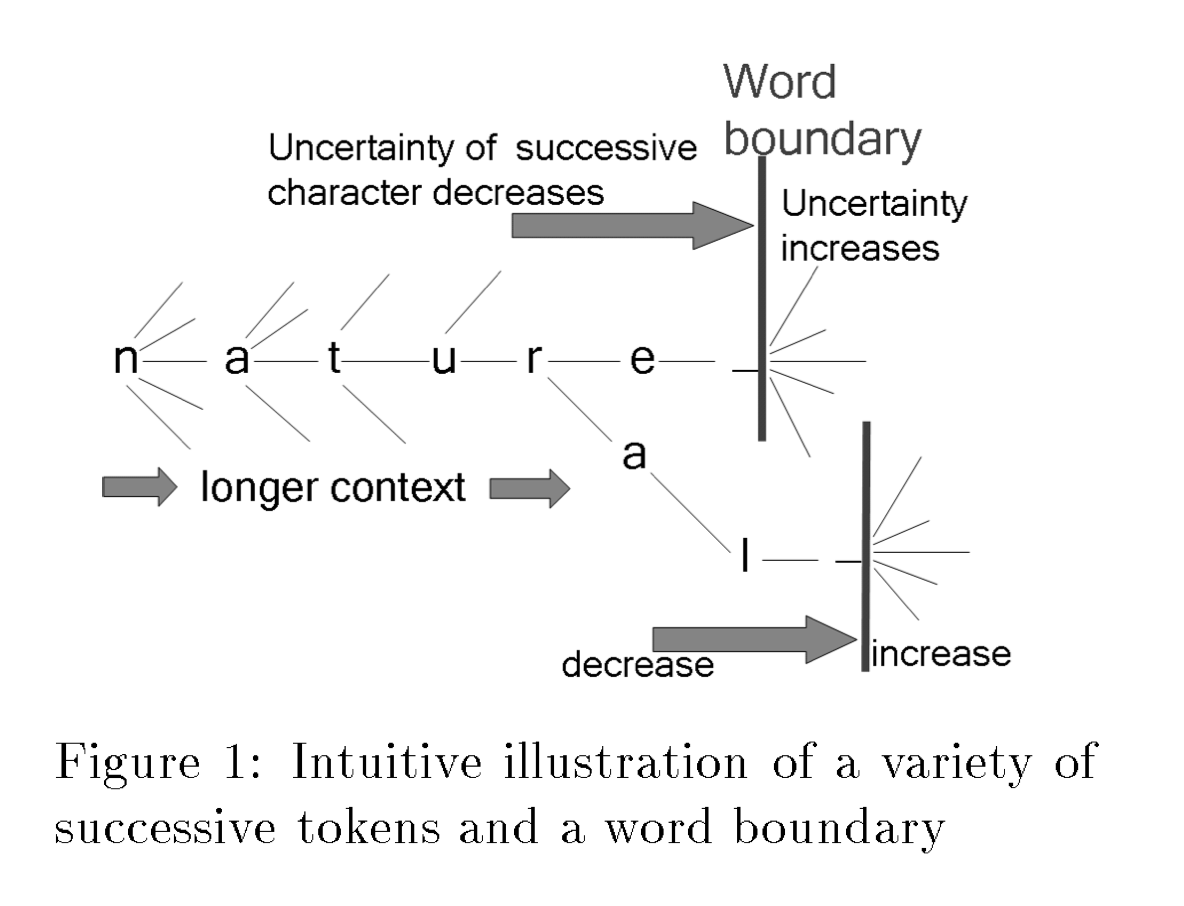
예를 들어 설명해보면 블로그라는 문자열 뒤에 의가 붙을 수도 있고, 가, 로, 와도 붙을 수 있는 등 많은 문자열이 붙을 수 있기 때문에 엔트로피가 높다. 그에 비해 블로라는 문자열 뒤에는 그라는 문자열이 붙을 확률이 높기 때문에 엔트로피가 낮아진다. 이처럼 엔트로피가 높은 지점을 단어 경계로 두는 방법이다.
디테일한 부분은 참고자료 섹션을 참고하면 쉽게 알 수 있다.
어떻게 진행해볼까
아래와 같은 리소스가 있는 상황에서 비지도로 신조어를 추출하고 싶었다.
- 빠르게 동작하고 커스텀이 가능한 형태소 분석기
- 해당 형태소 분석기용으로 구성된 도메인에 잘 맞는 사용자 사전
- 레이블링이 안 된 말뭉치
이미 잘 동작하는 형태소 분석기를 그대로 사용하고 싶었기 때문에, Word branching을 토큰 단위로 바꿔보았다. 이미 단어로 분리되는 띄어쓰기 단위로 나눈 뒤 subword를 문자처럼 취급하여 word branching을 적용했다.
진행 방법
- 우선 공개되어 있는 말뭉치에 대해 테스트해보기 위해 사용자 사전 없이 나무위키 말뭉치를 들고 왔다.
- 그리고 nori-clone으로 전부 형태소로 쪼개었다.
- 상황 별 frequency를 측정했다. frequency는 오른쪽에서 왼쪽으로, 왼쪽에서 오른쪽으로 각각 별도로 카운트했다.
- entropy를 측정한 후 높은 순으로 정렬해 상위 1000개를 추출했다.
200만 문장 정도만을 사용했고, 2단계부터 3단계까지 분석 시간은 랩탑에서 2분정도 소요되었다.
결과
아래는 왼쪽에서 오른쪽으로 카운트한 frequency에 대해 entropy를 계산한 결과이고, 상위 50개이다. 상위 1000개 단어는 내용은 아래 깃헙 링크에 존재한다.
| term | entropy |
|---|---|
| 에 ##어 | 3.7722856801778732 |
| 다 ##이 | 3.673823498311085 |
| 입주 ##ᆞ | 3.6718001177091875 |
| 일 ##일 | 3.5539066051545545 |
| 먹 ##튀 | 3.479139552269512 |
| 노 ##말 | 3.433385826872628 |
| 한 ##일 | 3.4295465607024296 |
| 네임 ##드 | 3.3689926734845637 |
| 스 ##트 | 3.322982790156606 |
| 일 ##베 | 3.2443194255873533 |
| 수 ##비 | 3.241800985524591 |
| 해 ##적 | 3.2345622133028753 |
| 넉 ##백 | 3.23042776698404 |
| 스 ##포 | 3.2228785888543907 |
| 개 ##화 | 3.2019979646703365 |
| 덕 ##후 | 3.2007311602719795 |
| 가 ##챠 | 3.1936780256704775 |
| 꾸역 ##승 | 3.1527067166833547 |
| 저 ##렙 | 3.14468026066866 |
| 한 ##거 | 3.1207967514794412 |
| 이 ##천 | 3.097727600510029 |
| 좀 ##비 | 3.096768549484737 |
| 드 ##랍 | 3.080990706222416 |
| 최종 ##보스 | 3.072646151053142 |
| 그런 ##거 | 3.0724632423496354 |
| 인간 ##이 | 3.068484634457483 |
| 친 ##박 | 3.067626785925482 |
| 점 ##화 | 3.0555455097944173 |
| 무력 ##화 | 3.052334423389574 |
| 리 ##마스터 | 3.04923555011575 |
| 궁 ##병 | 3.049061158784854 |
| 천 ##이 ##백 | 3.0389686073097573 |
| 해 ##보 | 3.0363083726713334 |
| 뚜벅 ##이 | 3.0277704386470834 |
| 신고 ##하 | 3.0251472429983592 |
| 운동 ##선수 | 3.019288605810868 |
| 팔 ##백 | 3.017503507608596 |
| 재 ##밍 | 3.017456611504466 |
| 구 ##백 | 3.0130928323492836 |
| 거대 ##화 | 3.0112684410697574 |
| 천 ##백 | 3.0034494584222453 |
| 다단 ##히트 | 3.002476600273605 |
| 신 ##형 | 2.9865144635097183 |
| 듀얼 ##리스트 | 2.986503498535038 |
| 하 ##는 ##거 | 2.985560711858541 |
| 고 ##렙 | 2.9801148168680323 |
| 아포 ##칼 ##립스 | 2.9787938589678804 |
| 투명 ##화 | 2.9781246387648683 |
| 형 ##님 | 2.9722102030688395 |
실제로 어떻게 분절되는지는 그대로 확인하고 싶어 각 suffix에 해당하는 토큰을 WordPieceTokenizer처럼 앞에 ##으로 표기해주었다.
생각보다 괜찮은 결과를 보이는 것 같고, 실제 말뭉치를 보았을 때 (물론 모두 확인해볼 수는 없지만) 꽤 괜찮은 결과라고 생각했다.
실제 필요한 경우 사용자 사전에 추가할만 하다고 생각한다.
아래는 오른쪽에서 왼쪽으로 세어본 토큰들의 엔트로피 결과이고, 상위 50개만을 가져왔다. 오른쪽에서 왼쪽으로 세면서 엔트로피가 높은 경우는 조사들의 조합 또는 어미들의 조합이 대부분일 것이라 생각했고, 실제로 그랬다.
| term | entropy |
|---|---|
| ##와 ##의 | 7.578974624427682 |
| ##와 ##는 | 7.400470597016048 |
| ##이 ##자 | 6.935379517767557 |
| ##이 ##라는 | 6.924268779922217 |
| ##에서 ##의 | 6.857848841758668 |
| ##하 ##고 | 6.805694279249581 |
| ##이 ##며 | 6.748122473402611 |
| ##만 ##을 | 6.687932935110919 |
| ##보다 ##는 | 6.684661396106697 |
| ##들 ##을 | 6.681373470169492 |
| ##하 ##는 | 6.680994741979571 |
| ##에서 ##는 | 6.675089917519511 |
| ##하 ##여 | 6.674611497152369 |
| ##하 ##거나 | 6.671039992924584 |
| ##이 ##기 | 6.651066461241131 |
| ##이 ##었 ##던 | 6.622526515902672 |
| ##에서 ##도 | 6.6166778796567325 |
| ##하 ##면서 | 6.600931648127071 |
| ##하 ##기 | 6.596867818280004 |
| ##과 ##의 | 6.593480025476041 |
| ##에 ##만 | 6.543063102860547 |
| ##들 ##이 | 6.542386834299748 |
| ##임 ##에 ##도 | 6.5057702971610745 |
| ##이 ##기 ##도 | 6.4881099798891135 |
| ##들 ##에 | 6.479950712565178 |
| ##답 ##게 | 6.478690598723199 |
| ##했 ##다고 | 6.469782511997774 |
| ##했 ##다는 | 6.454509134081455 |
| ##같 ##은 | 6.4461926710443045 |
| ##초등 ##학교 | 6.444289368477734 |
| ##와 ##도 | 6.433206977257026 |
| ##들 ##과 | 6.424783362080163 |
| ##하 ##게 | 6.405036978933993 |
| ##하 ##며 | 6.3845718275524845 |
| ##이 ##라 | 6.364467451804797 |
| ##에서 ##만 | 6.3395326316569225 |
| ##였 ##던 | 6.306683169317641 |
| ##했 ##던 | 6.289320445117414 |
| ##이 ##지만 | 6.277241990588663 |
| ##하 ##지 | 6.265151999421886 |
| ##들 ##로 | 6.262173494419509 |
| ##이 ##라고 | 6.258497743953773 |
| ##들 ##은 | 6.253009186851683 |
| ##로서 ##의 | 6.22704523731608 |
| ##하 ##다 | 6.225641133660668 |
| ##하 ##던 | 6.214481117805249 |
| ##뿐 ##만 | 6.212146380680863 |
| ##임 ##을 | 6.207317507933869 |
| ##하 ##기 ##로 | 6.196577090993401 |
| ##과 ##는 | 6.188861280658772 |
오히려 왼쪽에서 오른쪽으로 추출한 결과보다 깔끔하다는 생각이 들었다. 정제된 패턴으로 많은 글들이 쓰여진 결과로 보이고, 그래서 통계적인 방법으로 잡았을 때 깔끔하게 분리되는 것 같다.
마무리
머신러닝 모델을 아예 안쓰고 NLP 분석을 해보는 것이 참 오랜만인데, 최근에 회사에서 텀분절과 관련된 프로젝트(관련 블로그 글 - 제가 등록한 물건이 보이지 않아요: 텀분절)를 진행했다보니 더욱 신기한 느낌이 든다.
참고자료
- Unsupervised Segmentation of Chinese Text by Use of Branching Entropy
- https://lovit.github.io/nlp/2018/04/09/branching_entropy_accessor_variety/
- https://github.com/jeongukjae/nori-clone
- https://jeongukjae.github.io/tfds-korean/datasets/namuwiki_corpus.html
이 포스트를 작성하기 위해 사용했던 모든 스크립트는 GitHub - jeongukjae/branching-entropy-with-pos-tagger에 존재한다.