MLIR 이야기
TensorFlow에 포함되어 있을 적부터 흥미있게 보았던 프로젝트. ML은 Machine Learning이 아닌 Multi-Level을 말한다. 해당 논문이나 관련 프로젝트를 찾아보고 정리해본다.
공유용보다는 회사에서 스터디했던 내용을 블로그에 아카이브하는 용도이다. IR 디자인을 어떻게 했는지를 공부하려고 읽은 것은 아니고, MLIR에 대한 백그라운드 정리, 관련 프로젝트를 정리했다.
- MLIR: Scaling Compiler Infrastructure for Domain Specific Computation - Google Research
- MLIR LLVM 페이지
Background
MLIR은 현재 다양한 머신러닝 프로젝트에 통합되는 중이고, 현재는 TensorFlow, Jax에 통합되어 있다. 그 외에 iree가 주목할만한 프로젝트라고 생각하는데, iree는 IR 실행 환경을 위한 프로젝트이다.
- TensorFlow는 MLIR로 전환 중: TensorFlow MLIR
- Jax의 Compiler 또한 MLIR 기반: https://github.com/google/jax
- iree 👻: https://github.com/google/iree

Introduction
- Motivation
- 이미 많은 Best practice가 쌓여가는 컴파일러 세계에서 두각을 나타내는 재사용성. LLVM compiler infrastructure 혹은 JVM의 one size fits all 방식의 접근법
- LLVM의 경우에는 IR을 제공하고, C with vectors 정도의 방식
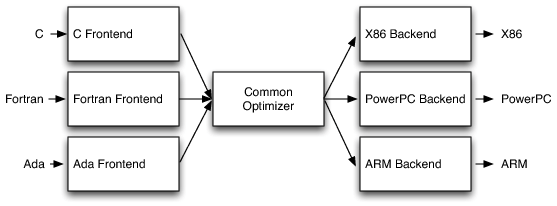
- JVM은 object oriented type system & GC 정도의 방식
- LLVM의 경우에는 IR을 제공하고, C with vectors 정도의 방식
- 하지만 해당 방법은 큰 문제가 존재한다.
- ex) LLVM IR을 통해 C++의 source-level 분석같은 것을 할 경우 매우 어려움
- ex) domain specific IR일 경우 IR 설계가 완전히 달라짐 → 기존 인프라 사용이 어려워짐
- domain-specific IR은 개발하기 어렵지만, 개발자들에게 이 문제는 높은 우선순위가 아님
- 결과 → this can lead to lower quality compiler systems, including user-visible problems like slow compile times, buggy implementations, suboptimal diagnostic quality, poor debugging experience for optimized code, etc.
- 이미 많은 Best practice가 쌓여가는 컴파일러 세계에서 두각을 나타내는 재사용성. LLVM compiler infrastructure 혹은 JVM의 one size fits all 방식의 접근법
- 그래서 MLIR은 이 문제를 바로 해결하려고 한다.
- 이러한 비용을 값싸게 만들고, abstraction level을 새롭게 제공하면서도, 기존 컴파일러 인프라를 그대로 활용할 수 있도록.
어떻게?
- standardizing the Static Single Assignment (SSA)-based IR data structures
- providing a declarative system for defining IR dialects
- providing a wide range of common infrastructure including documentation, parsing and printing logic, location tracking, multithreaded compilation support, pass management, etc.
- 아래와 같은 정책을 가질 것
- Parsimony: 빌트인을 적게 유지하고, 커스터마이즈, 확장성을 주로 고려한다.
- Tracability: 디버깅, 오류 스택 트레이스 등등에서 오류가 발생했을 때 거꾸로 올라가서 복구하는 방법보다 미리 정보를 저장하는 방법을 사용하겠다.
- Progressively: 미리 모든 representation을 lowering하는 것은 나쁘다.
- allow multiple transformation paths that lower individual regions on demand.
- 이러한 비용을 값싸게 만들고, abstraction level을 새롭게 제공하면서도, 기존 컴파일러 인프라를 그대로 활용할 수 있도록.
어떻게?
- 근데 MLIR 왜 시작했어요?
- 현대의 머신러닝 프레임워크가 너무 많은 컴파일러, 그래프 기술, 런타임 시스템을 가지고 있다는 것이 보여지면서, 이걸 공통된 infrastructure/디자인으로 묶을 수 없을까?에 대한 대답.
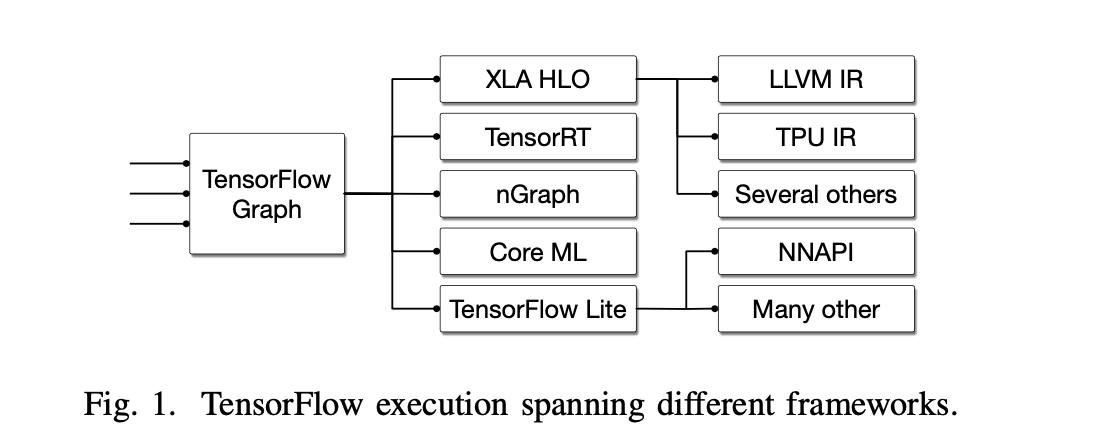
- 현대의 머신러닝 프레임워크가 너무 많은 컴파일러, 그래프 기술, 런타임 시스템을 가지고 있다는 것이 보여지면서, 이걸 공통된 infrastructure/디자인으로 묶을 수 없을까?에 대한 대답.
Design Principle
Little Builtin, Everything Customizable [Parsimony]:
- 기본 컨셉을 미니멀하게 유지하고 IR의 대부분을 Customize할 수 있도록 만듦
- 현재 우리가 알지 못하는 미래의 문제를 Customizable한 특성을 통해 해결한다.
- IR을 reusable한 컴포넌트를 많이 만들고, 기본 뼈대는 간결하게 유지하면서 문제를 풀어나가야 함
SSA and Regions [Parsimony]:
- SSA(Static Single Assignment)는 컴파일러에서 많이 쓰이는 패턴 중 하나.
- 각 변수는 해당 Region에서 정확히 한번만 할당
- 이 개념은 Dataflow에 대한 분석을 심플하게 만듦
- Region은 많은 IR이 flat한 region을 사용하는 반면, MLIR은 Nested Region을 사용 가능하게 함.
- 단순히 region을 더 추상화하는 것이 아니라 아래와 같은 일이 가능해짐
- 컴파일 과정 혹은 instruction 추출의 가속화
- SIMD parallelization의 가속화
- 그를 위해 어느정도 표준화(normalization) 또는 LLVM의 canonicalization properties는 희생해야함
- ex) canonical loop structure:
for (pre-header; header; latch) body
- ex) canonical loop structure:
- 단순히 region을 더 추상화하는 것이 아니라 아래와 같은 일이 가능해짐
Maintain Higher-Level Semantics [Progressivity]:
- 성능 최적화 혹은 디버깅, 오류 트레이스를 위해 higher-level semantics에 접근할 수 있어야 함
- MLIR은 IR을 점차 lowering 해가기 때문에 정보를 보존하면서 갈 수 있음
- 근데 잘 생각해보면 Multi-level IR은 해당 정보를 유지하기 위해 필요한 구조
Declaration and Validation [Parsimony and Traceability]:
- 그래프 최적화를 위한 transformation rule들을 declarative 하게.
- rewriting system은 이미 잘 작성된 것이 많지만 declarative 한 것은 많지 않고, 그렇게 작성할 경우 확장성과 재현성에서 큰 이득을 가져올 수 있음.
- 또 이러한 시스템을 구현할 경우 validation 측면에서도 좋은 결과를 가져올 수 있음
Source Location Tracking [Traceability]:
- Maintain Higher-Level Semantics와 거의 비슷한 말.
IR Design
패스
Evaluation: Applications of MLIR
TensorFlow Graphs
- 내부 표현을 나타내기 위해 MLIR을 사용 중
- 간단한 algebraic optimziation부터 parallel, distributed execution까지 최적화 가능
- 모바일 배포부터 domain specific한 XLA 배포까지 가능
- Grappler에 표현된 모든 transformation 코드는 MLIR로 표현가능.
- dead code elimination, constant folding, canonicalization, ..
Consequences of the MLIR Design
Reusable Compiler Passes
- Transformation path는 모든 Op을 알 필요가 없고 특정 Op들의 Trait에 의존하는 경향을 보임
- ex) dead code elimination은 해당 코드가 terminator인지만 검사
- 그러한 compiler passes를 재사용 가능
Parallel Compilation
- Trait을 기반으로 컴파일 속도를 향상시킬 수 있음
- ex> isolated from above가 있는 경우 분리해서 컴파일
Interoperability
- 기존 시스템들의 interoperability 향상 가능
- ONNX 처럼
February 19, 2022
Tags:
llvm
tensorflow