Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding 리뷰
이 논문이 나오기 얼마 전에 마이크로 소프트에서 나온 MT-DNN (Liu et al., 2019)에 Knowledge Distillation을 적용한 논문이다. arvix링크는 https://arxiv.org/abs/1904.09482이고 코드는 GitHub - namisan/mt-dnn에서 확인 가능하다. 특이하게 다른 Distillation 방법들과는 다르게 Teacher 모델을 여러개 만들어두고 teacher들을 ensemble하여 student 모델을 학습한다. 즉, 모델 압축을 위해 KD를 사용하는 것이 아니라, 모델 성능을 높이기 위해 Ensemble된 모델들을 KD를 사용하는 것이다.
1. Introduction
- Ensemble 모델은 model generalization을 향상시키는데 효과적인 방법
- 최근 NLU SOTA나, QA, Reading Comprehension의 SOTA도 Ensemble을 많이 이용한다.
- 하지만, 배포하기에는 너무 비싼 연산이다.
- Bert, GPT가 최근 fine tuning을 통해 많은 모델에 쓰이고 있는데, 그 자체로도 비싼 연산인 모델을 ensemble해버리면 배포가 불가능한 수준이다.
- 그래서 Ensemble을 할 수 있게 Teacher를 여러개 학습하고 이를 KD한다.
- 결과적으로 distillation된 MT-DNN이 vanilla MT-DNN보다 더 좋은 성능을 낸다.
2. MT-DNN
- MT-DNN 관한 설명이라 패스
- Multi-Task Deep Neural Networks for Natural Language Understanding를 읽자
3. Knowledge Distillation
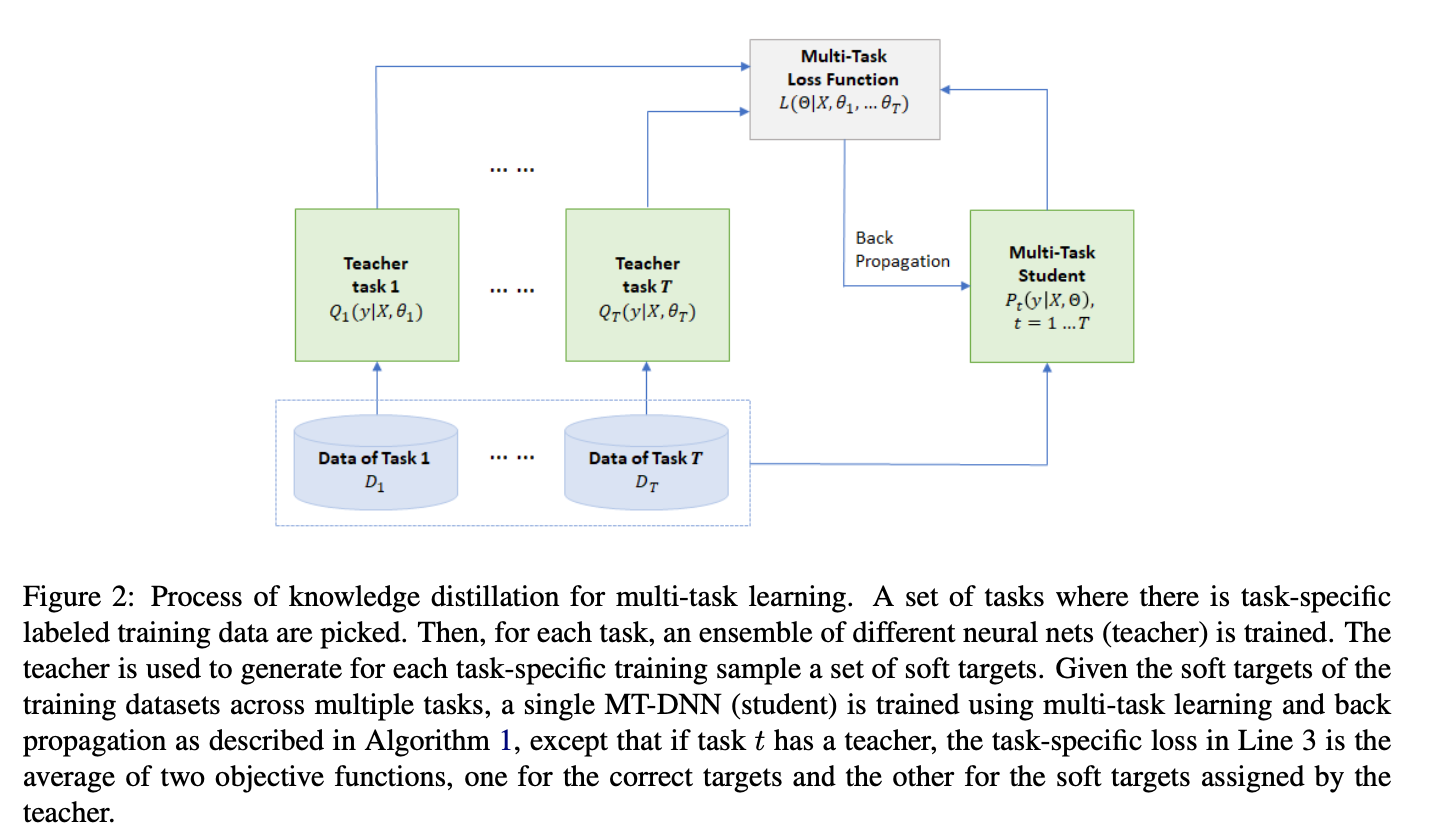
- Multi Task Learning을 Distillation하는 것은 위 그림을 참고.

- 각 Teacher Task는 Algorithm 1을 따라감
- teacher가 생성해내는 Soft Target: \(Q = \text{avg} ([Q^1, Q^2, ..., Q^K])\)
- 위의 soft target을 근사하고 싶은 것.
-
Student의 Task specific layer output \(P_r (c \vert X)\)에 대해 아래와 같은 loss를 적용함
\[- \sum_c Q(c\vert X) \log (P_r(c\vert X))\]
-
- 원래 MT-DNN은 Cross Entropy Loss를 사용하는데, hard correct target에 대해서 Student Loss에 더해주려다가 그닥 성능 향상을 얻지 못해서 안했다고 한다.
- 물론 아래에 서술되어 있듯이 Teacher가 없는 태스크가 존재하는데, 이러한 태스크들은 일반적인 MT-DNN 학습방식을 따름
4. Experiments
- GLUE를 BERT (Devlin et al., 2018), STILT (Phang et al., 2018), MeTal Hancock et al., 2019, MT-DNN (Liu et al., 2019)과 비교
4.1. Implementation details
- Adamax 사용
- task specific한 dropout 사용
- gradient norm을 1안으로 clip함
- Ensemble할 때
- Cased, Uncased 사용
- 다른 dropout rate 사용
- MNLI와 RTE에서 최고 성능을 내는 모델 3개 선정
- 3개 모델을 MNLI, QQP, RTE, QNLI에 대해서 fine tuning
- 각 태스크는 3개의 Teacher를 가지는 셈이다.
- 다만, 위 네개 태스크를 제외하고는 teacher 없이 학습된 것
4.2. GLUE Main Results
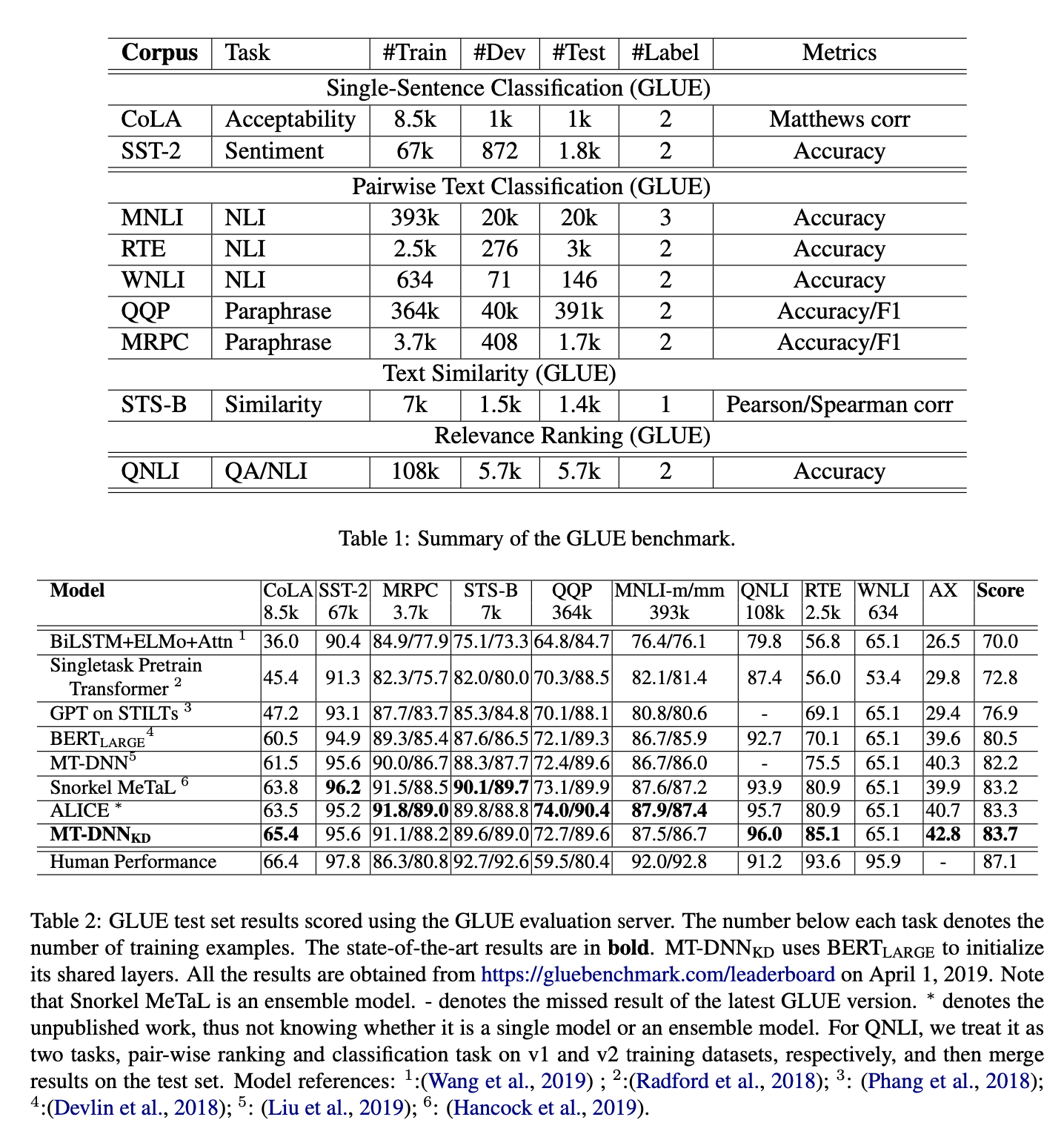
- Teacher가 없는 태스크까지 MT-DNN보다 잘 함
- 또한 CoLA, RTE의 경우에는 큰 폭으로 향상됨
4.3. Ablation Study
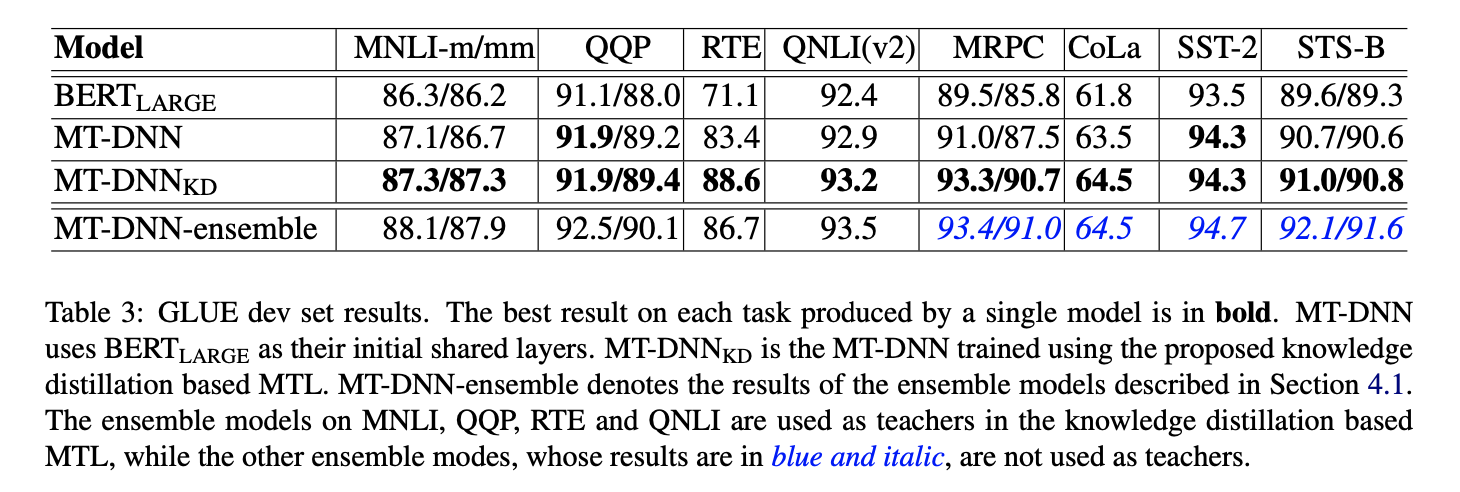
- 위 표를 보면 알 수 있듯이 일반 MT-DNN보다 훨씬 잘함
- RTE 같은 경우는 특히 놀라운 성능
5. Conclusion
- soft target과 hard correct target을 더 잘 사용할 방법을 찾자
- teacher를 unlabeled data에서 soft target을 생성해내도록 만들어 semi-supervised learning을 더 돌릴 수 있을 것 같다.
- 모델 압축하는 대신 KD는 모델 성능 향상에도 큰 기여를 할 수 있다.
___
- 모델 크기를 줄였으면 어떘을까?
- 실제로 다른 태스크까지 Teacher로 사용했다면?
April 16, 2020
Tags:
paper