Smart image cropping using self-attention
가볍게 기록해보는 이미지 크롭에 방식에 대한 고민. 보통 object-fit으로만 사용하는 미리보기 이미지를 머신러닝을 사용하여 좀 더 이쁘게 뽑아줄 수 없나? 데이터 없이 self supervised 이미지 모델의 self-attention만 사용해도 뽑을 수 있으면 더 좋고.

다른 곳은 어떻게 할까?
트위터에서 블로그 포스트로 공개한 Speedy Neural Networks for Smart Auto-Cropping of Images을 보고 아이디어가 떠올랐다. 저 글의 요지는 1) 사람이 주목하는 부분을 데이터로 수집하고 2) 해당 부분을 추론하도록 모델을 학습하여 3) 트윗 프리뷰 이미지를 모델을 이용해 만들어주었다는 것이다.

https://blog.twitter.com/engineering/en_us/topics/insights/2021/sharing-learnings-about-our-image-cropping-algorithm
근데 이게 윤리적인 문제는 있다고. 아이트래커를 사용해 데이터를 수집했으니 사람들의 편향이 당연히 들어갔을 것 같긴 하다.
Dino 모델
근데 내가 당장 아이트래커를 가져올 수는 없으니 어떻게 테스트해볼지 생각해봤다. 1) object detection을 활용해 잡는 방법 2) self attention을 이용해 잡는 방법 두가지가 생각났고, self attention이 더 무난하게 잡을 것 같아 그 쪽으로 결정했다.

https://ai.facebook.com/blog/dino-paws-computer-vision-with-self-supervised-transformers-and-10x-more-efficient-training/
그래서 어떤 모델을 가져올지 고민하다가 self supervised 방식으로 학습한 DINO 모델이 떠올랐고 성능이 중요한 것은 아니니 제일 작은 DINO 모델(vit-small-16patch)를 가져와서 진행했다. 여기서 생각한 가정은 “DINO가 잡는 부분이 사람들이 주목하고 싶은 부분과 비슷할 것이다!”라는 것.
진행
진행한 방식은 다음과 같다.
- 적당한 이미지를 가져온다. (Unsplashed에서 많이 가져왔다)
- DINO 모델로 self attention 값을 추출한다.
- 주변 픽셀 값을 활용해 적절히 뭉갠다. (outlier 값들이 있을 수 있으니)
- 제일 높은 값을 가진 픽셀 위치를 위주로 crop 한다.
여기서 3이 크게 의미있는 과정인지는 모른다. 비전 관련해서 깊게 공부해본 적이 없기 때문에 필요하면 개선이 가능할 것 같아 패스했다.
결과
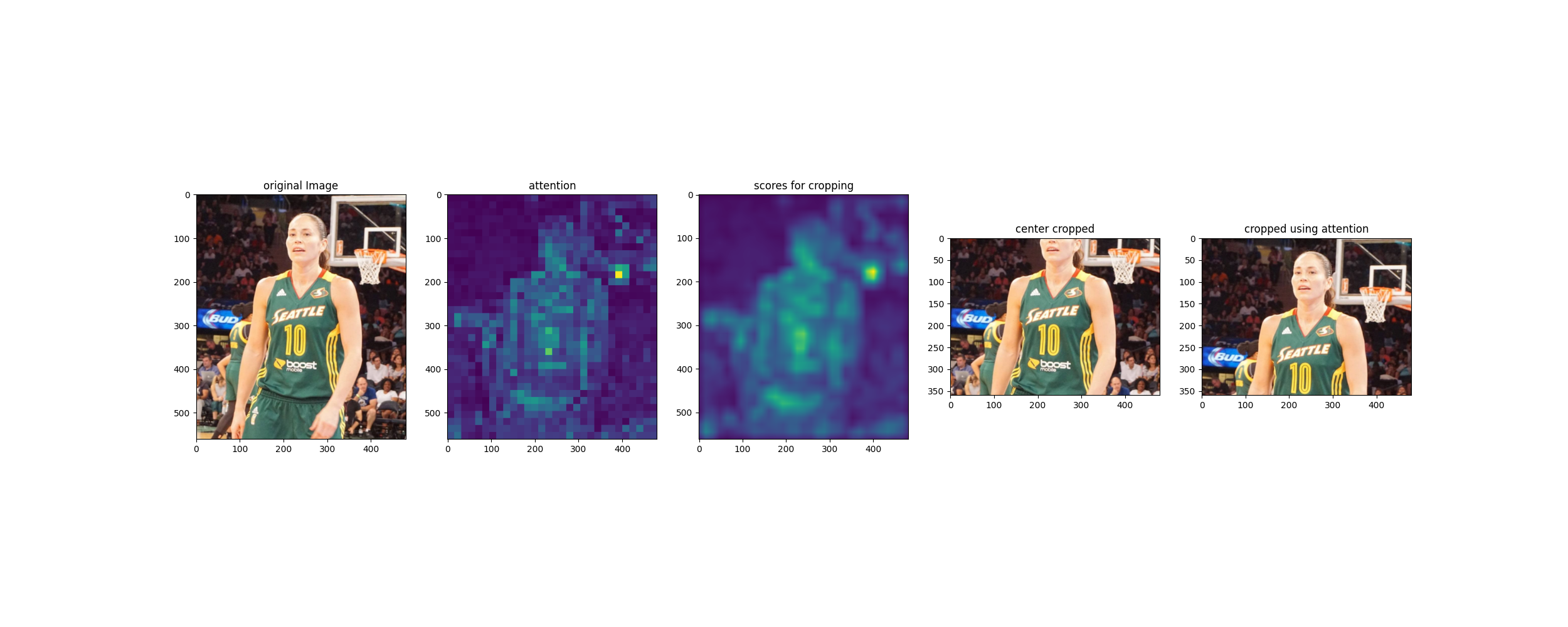
Unsplashed를 켜서 보이는 사진 적당히 5개 정도 가져와서 샘플만 뽑아보았다. 각 행별로 첫번째 이미지가 원본 이미지, 두번째 이미지가 attention 값, 세번째 이미지가 box blur한 값, 네번째 이미지는 center crop한 값, 마지막 이미지가 attention 정보를 활용해 crop한 이미지이다.




강아지 사진들 경우는 당연히 잘 될 것 같았고 잘 됐다. 서핑복 입은 남성 사진이 잘 안될 것 같았는데 다행히 은근 잘 잘렸다.
오브젝트가 길게 위치하는 이미지 혹은 여러 오브젝트가 등장하는 이미지는 어텐션이 여러 곳에 분포해서 이상하게 잘릴 것 같다. 예를 들어 트위터 블로그 포스트의 예시는 그렇게 잘 잡히지는 않는다. 아래 이미지인데, 얼굴쪽으로 잘 잘린 것 같지만, 잘 보면 농구대 네트쪽이 높은 attention 값을 가지고 있다.
–
코드는 GitHub Repository에 있다. https://github.com/jeongukjae/image-cropping-using-attention