FastBERT: a Self-distilling BERT with Adaptive Inference Time 리뷰
이 논문 역시 BERT가 너무 서빙하기 큰 모델이라서 fine tuning 시에 self distillation을 적용해본 것이다. 2019 Tencent Rhino-Bird Elite Training Program에서 펀딩받아서 작성한 것이다. arxiv 링크는 https://arxiv.org/abs/2004.02178이다.
1. Introduction
- 최근 2년정도에 BERT, GPT, XLNET이 나왔지만, acc는 올려도 너무 느리다.
- 그래서 speed-accuracy balance를 맞추기 위해 quantization, weight pruning, knowledge distillation들이 적용되고 있는 중이다.
- sample wise adaptive mechanism을 적용한 FastBERT를 제안
- 실험은 Chinese, English NLP Task에 대해 각각 6개씩 실행했다.
- main contribution
- speed tunable BERT model 제안.
- sample-wise adaptive mechanism, self distillation mechanism을 제안
- 코드는 논문 publish된 뒤에 autoliuweijie/FastBERT에 공개 (아마 엑셉되고..?)
2. Related Work
- BERT-base는 110M 파라미터 & Transformer block 12개 쌓은 구조
- 너무 느리대요
- Knowledge Distillation
- PKD-BERT - incremental extraction process
- TinyBERT - two stage learning
- DistilBert - triple loss 로 distillation
- Adaptive inference
- (Graves, 2016) - token-wise, patch-wise로 각각의 토큰에 recurrent step 도입
- (Figurnov et al.) - CV에서 다이나믹하게 계산하는 레이어 조정
3. Methodology
3.1. Model Architecture
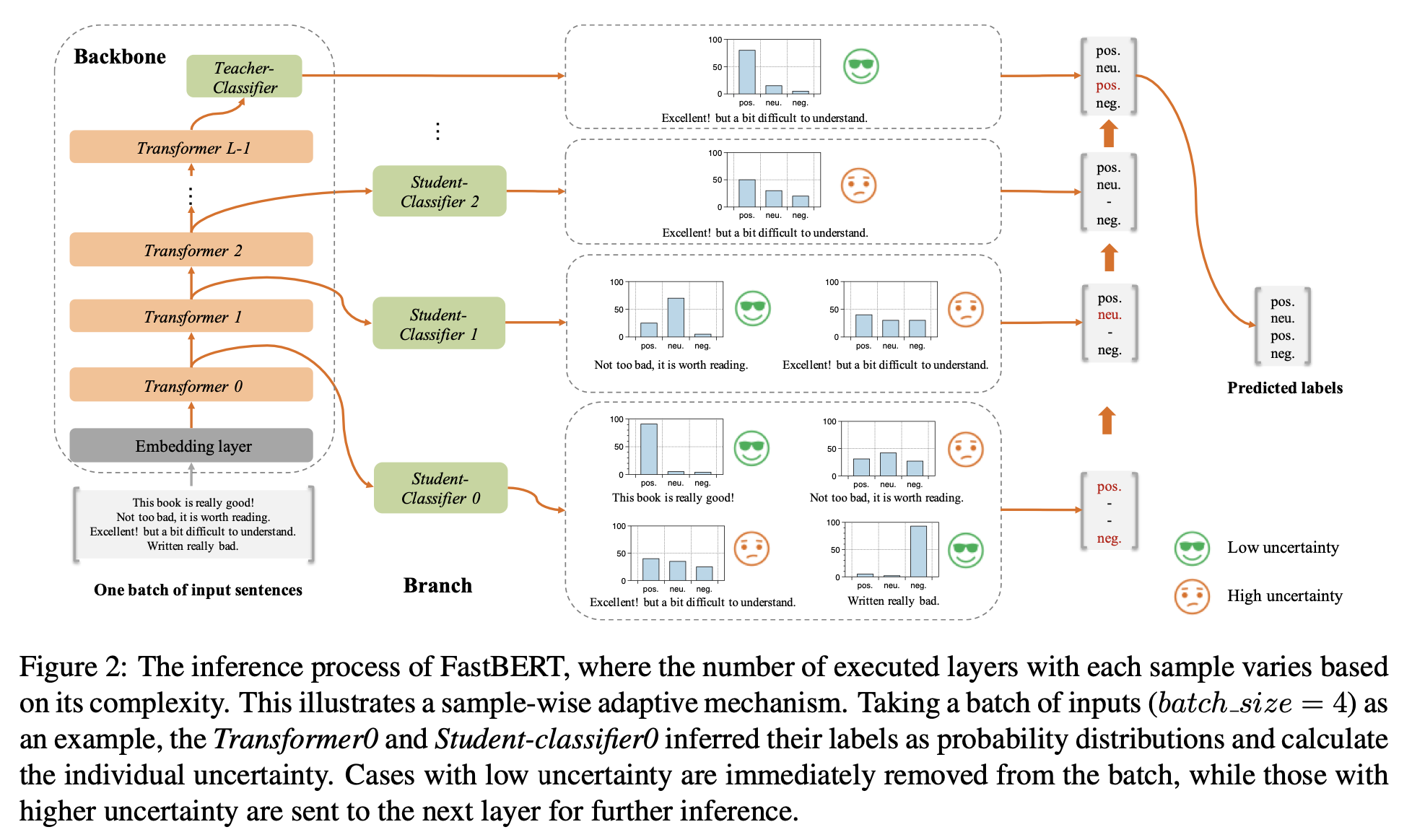
- Backbone + Branch로 구성
- Backbone은 그냥 BERT
- Branch는 각 transformer encoder block 결과에서 따오는 레이어
3.1.1. Backbone
- 세 부분으로 구성
- Embedding Layer
- Transformer Encoder Layer
- Teacher Classifier
3.1.2. Branches
- 여러개의 Branch가 존재
- 각 Transformer Layer가 0부터 시작하는 숫자로 번호가 부여되고, 그 레아어의 output이 \(h_i\)라 할 때 i번째 Student의 classification 결과:
- \[p_{s_i} = \text{Student_Classifier}_i(h_i)\]
3.2. Model training
- 세가지로 구성
- Major backbone pre-training
- Entire backbone fine-tuning
- Self distillation for student classifiers
3.2.1. Pre-training
- 그냥 Pretrain한다.
- BERT-like한건 쓸 수 있을 듯?
- BERT-WWM, RoBERTa, ERNIE
- BERT-like한건 쓸 수 있을 듯?
3.2.2. Fine-tuning for backbone
- Backbone + teacher classifier 학습
3.2.3. Self-distillation for branch
- 이제 Student classifier 학습
-
각 \(p_s\) - \(p_t\) (teacher) 사이의 loss를 아래처럼 계산 (KLL Divergence)
\[D_{KL}(p_s, p_t) = \sum^N_{i=1} p_s(i) \log \frac {p_s(i)} {p_t(j)}\] -
Layer가 L개 있으면 L-1개만큼 student classifier가 있기 떄문에 total loss는 아래처럼 계산
\[\text{Loss} (p_{s_0}, ..., p_{s_{L - 2}, p_t}) = \sum ^ {L-2} _ {i = 0} D_{KL} (p_{s_i}, p_t)\]
3.3. Adaptive inference
- 가설 1. Uncertainty가 낮을수록 Accuracy가 높다.
- 정의 1. Speed: high, low uncertainty를 구별하는 threshold
- uncertainty threshold가 낮을수록 low uncertainty를 요구하기 때문에 더 느린 모델이 나온다.
-
각각의 Uncertainty를 계산 (N -> # of labeled classes)
\[\text{Uncertainty} = \frac {\sum^N_{i=1} p_s(i) \log p_s(i) } {\log \frac 1 N}\] - 적절한 uncertainty를 얻을 때까지 higher layer로 간다.
- Transformer 한번 더 연산하는 것보다 classifier + uncertainty 계산이 더 빠르니 그거 계산해서 미리 결과 내겠다는 전략
4. Experimental results
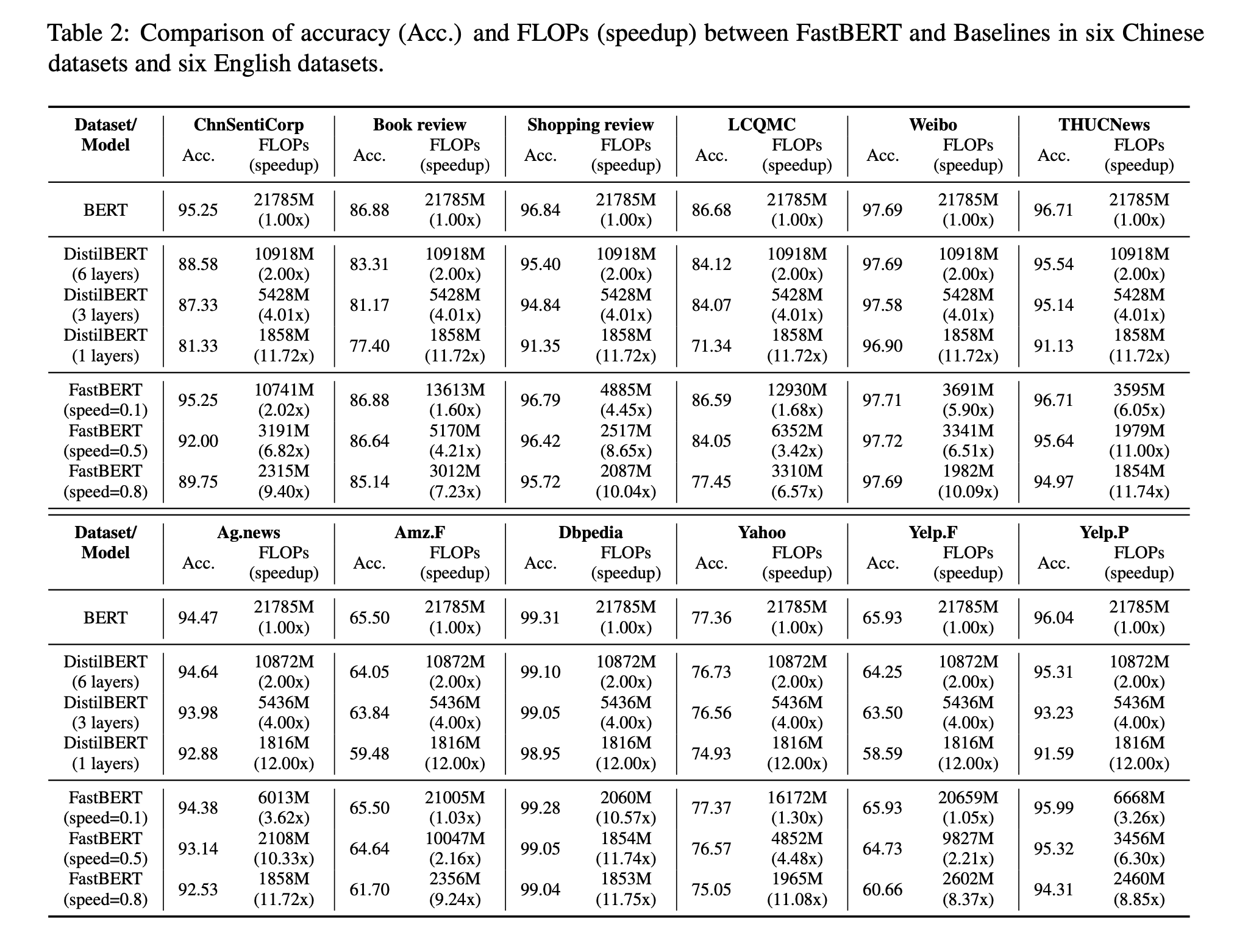
4.1. FLOPs analysis
- 생각보다 좋은 결과
- 특히 Dbpedia같이 쉬운 태스크의 경우에는 speed를 0.1만 줘도 굉장히 빠른 속도를 내면서도 높은 성능을 유지하는 것을 볼 수 있다.
- 성능을 임의로 조정하면서 속도-정확도를 가늠할 수 있는 것이 좋은 점
- 표에서 볼 수 있듯 BERT, DistilBERT를 baseline으로 잡음
4.3. Performance comparison
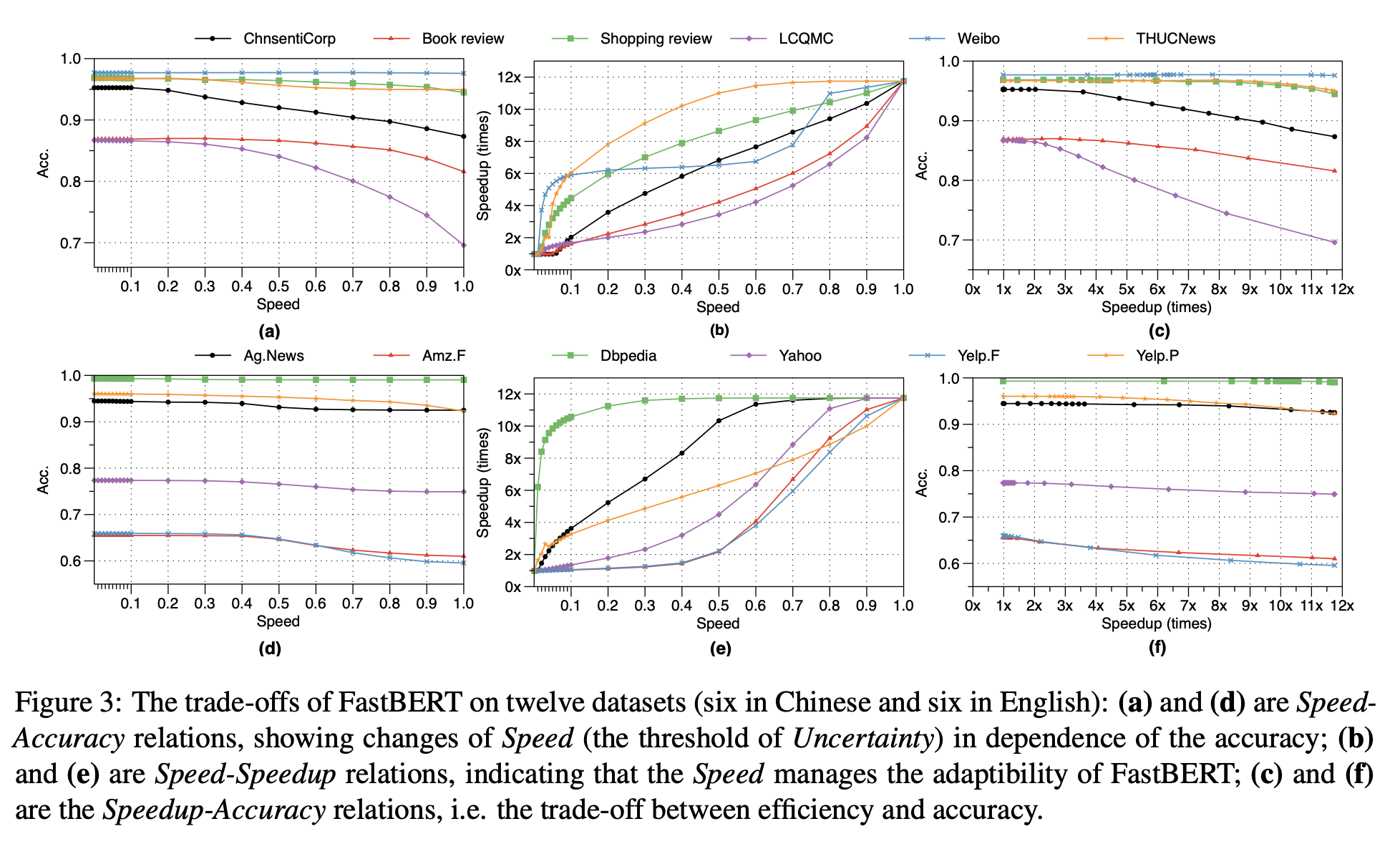
- Speed - Acc 그래프를 보면 적정한 임계치만 잘 잡으면 웬만한 fine tuning다 괜찮을 듯
4.4. LUHA hypothesis verification
- 아까 가설 검증하는 것인데, 충분히 실험적으로 잘 증명된 것으로 보임
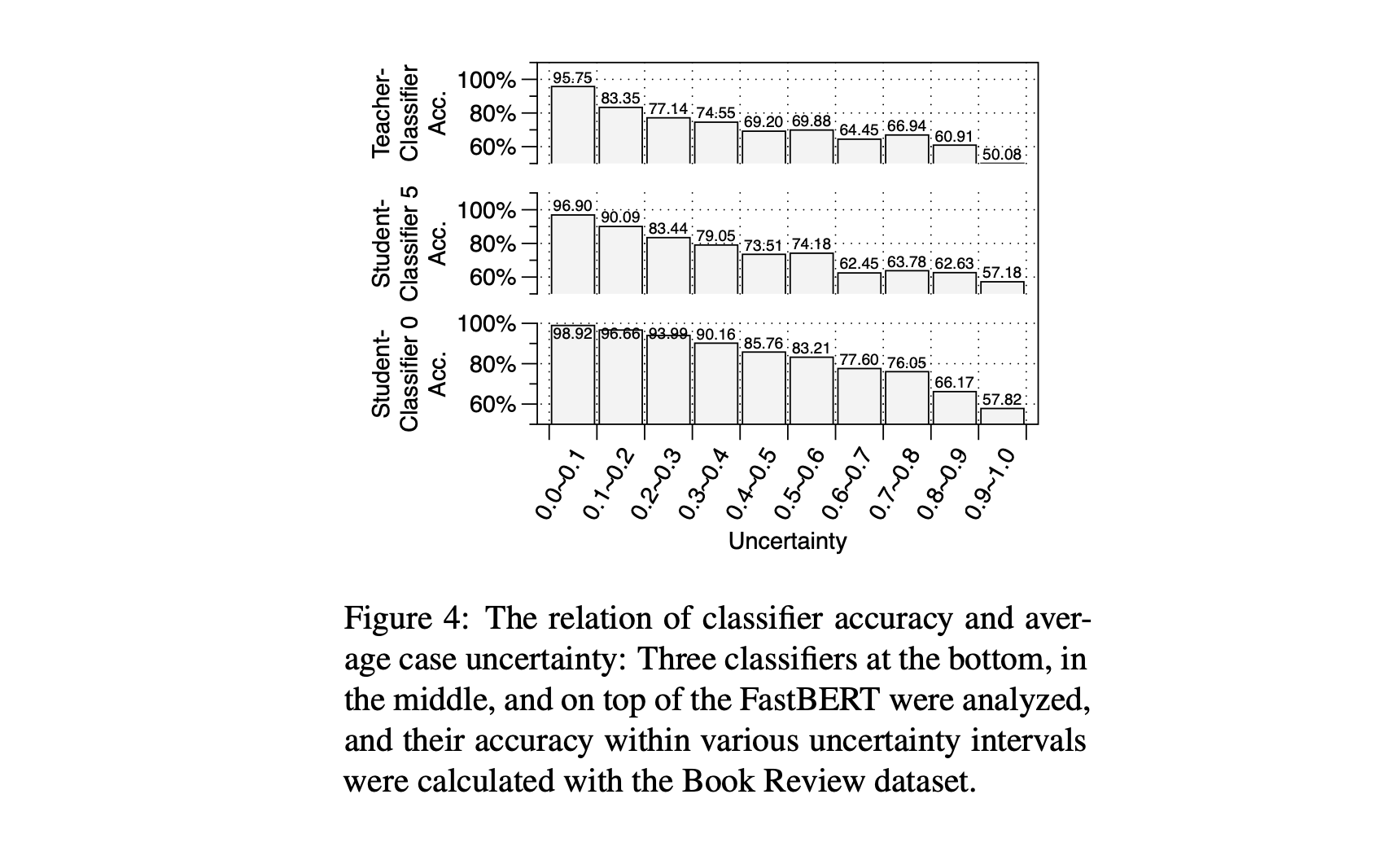
- 근데 그럼 Student만 쓰는 것으로 Teacher보다 괜찮은 성능 낼 수 있지 않나? 싶은데 아님. 아래를 잘 보자
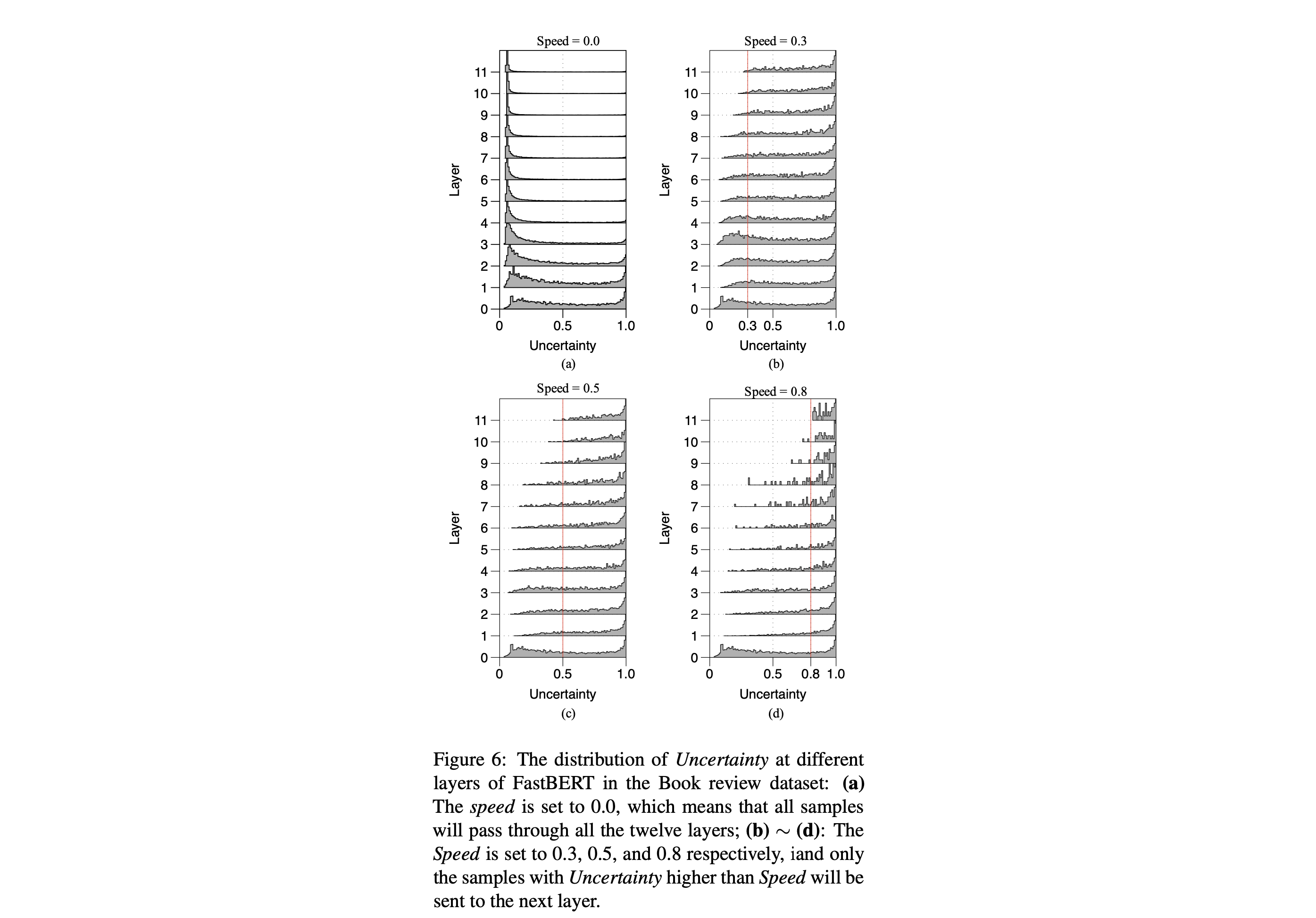
4.5. In-depth study
- 아래 세개 in-depth analysis 진행함
- the distribution of exit layer
- the distribution of sample uncertainty
- the convergence during self-distillation
4.5.1. Layer distribution

- 위 표를 보면 Book review dataset에서 speed 0.8, 0.5, 0.3을 설정했을 때의 각각 exit layer의 distribution
- 0.8을 설정할 경우 평균 1.92개의 레이어만 타고도 잘 동작한다.
- 또한 61% 정도는 하나의 레이어만 타도 잘 결과가 나온다.
4.5.2. Uncertainty distribution
- 다시 위 사진을 보면 Uncertainty distribution을 볼 수 있다
- high-layer가 low-layer보다 decisive(결정적??)이다.
4.5.3. Convergence of self-distillation
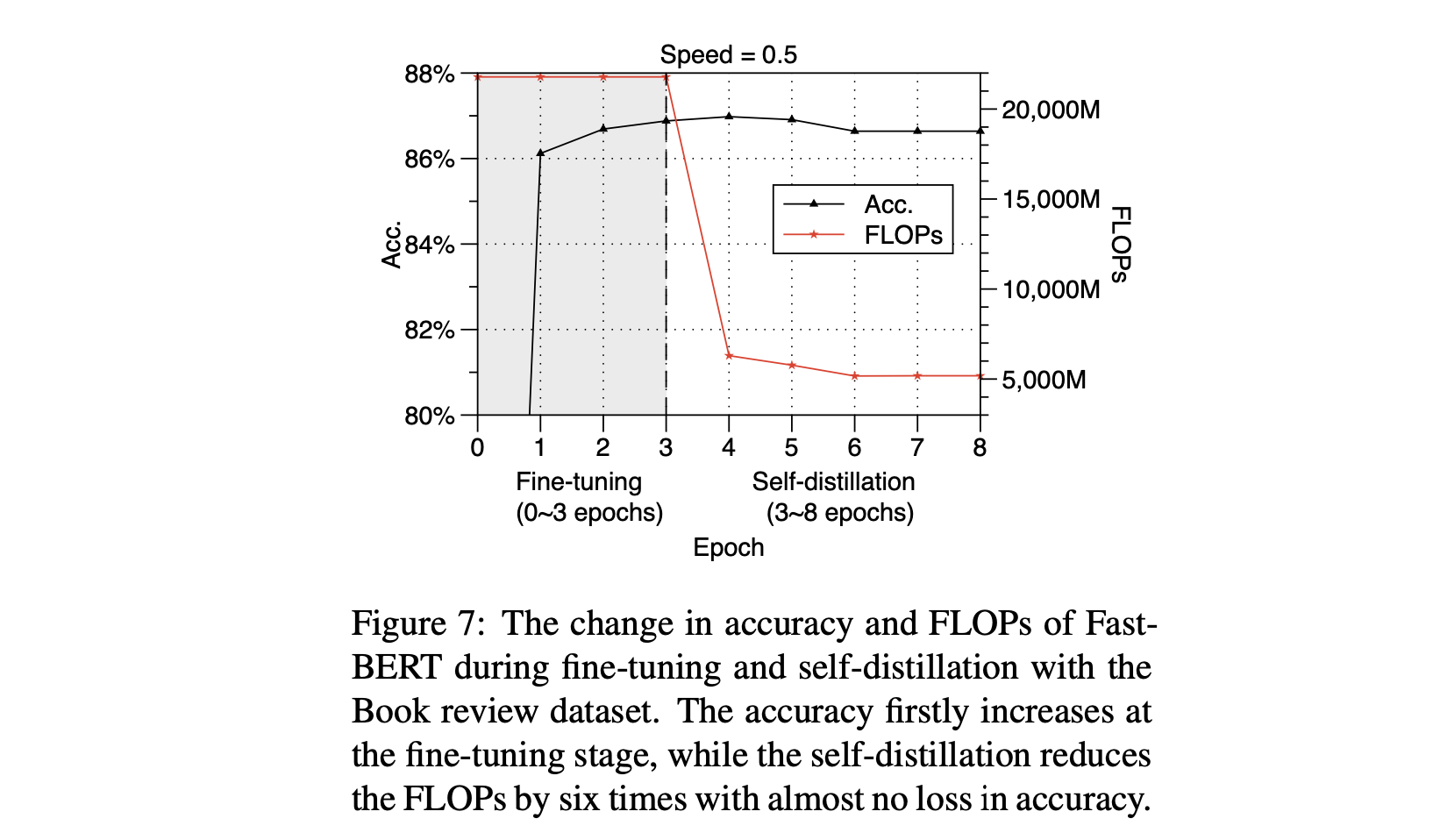
- 위 사진을 보면 acc는 fine-tuning 동안 올라가고 self distillation 동안 많이 떨어지는 것을 볼 수 있다.
4.6. Ablation study
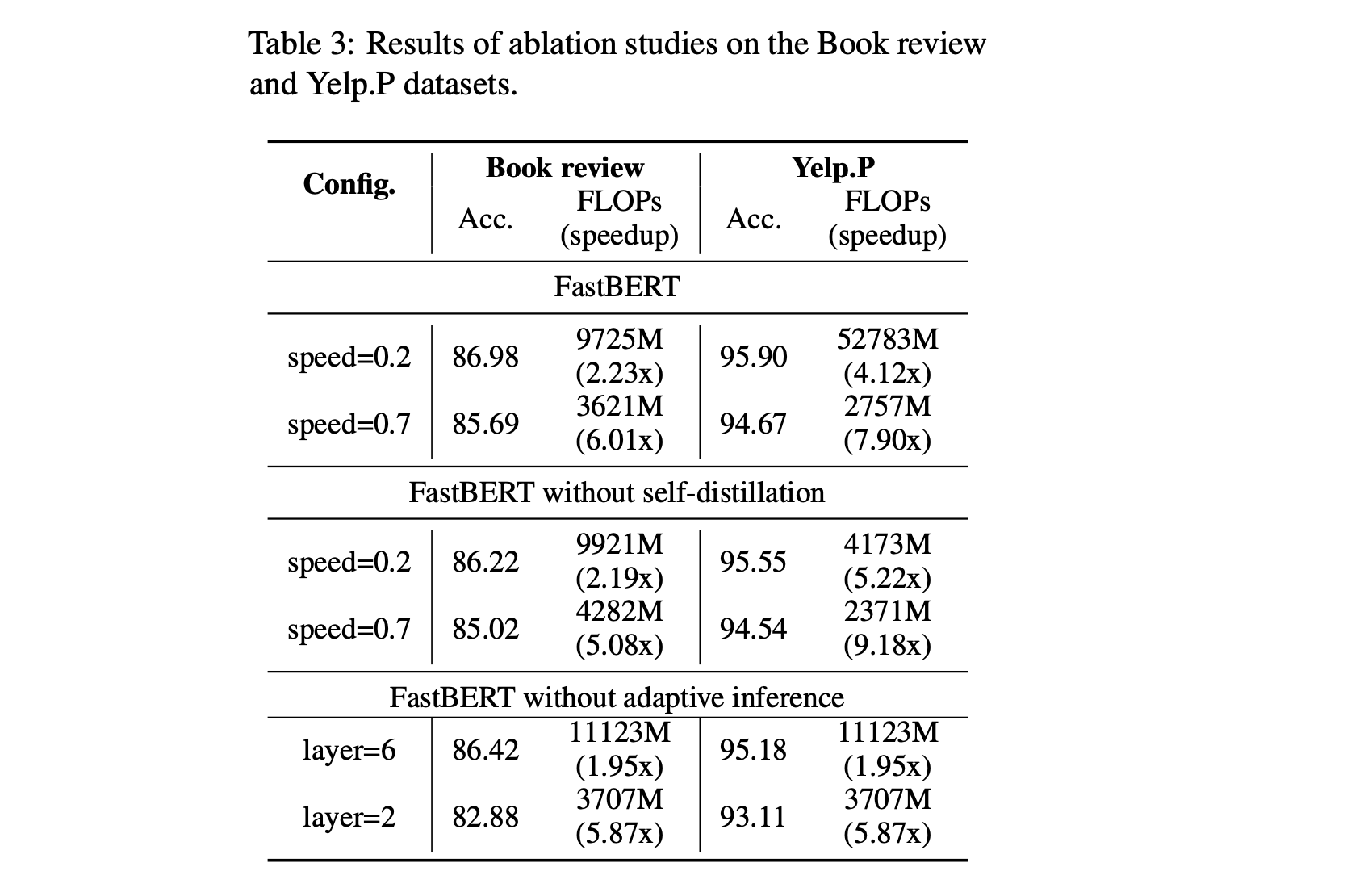
- 위 사진의 ablation study의 결과이다.
- 아마 Yelp.P의 FastBERT - speed=0.2의 FLOPS는 오타일듯…
- self-distillation + adaptive inference가 제일 좋은 성능을 내었다.
- 논문이랑 조금 다른 의견이긴 하지만, 너무 쉬운 태스크의 경우에는 self distillation 안해도 되지 않을까??
- Yelp.P에서 without self-distillation이 합리적인 acc - speed up 밸런스인듯 하다.
5. Conclusion
그냥 정리한 섹션
6. Future work
- linearizing the Speed-Speedup curve
- extending this approach to other pre-training architectures (such as XLNET, ELMO)
- applying FastBERT on a wider range of NLP tasks
April 14, 2020
Tags:
paper