CS224n Lecture 5 Dependency Parsing
CS224n 다섯번째 강의를 듣고 정리한 포스트! Assignment 2가 끝났고, Assignment 3가 시작되었다.
Syntactic Structure: Consistuency and Dependency
linguistic structure에는 두가지 관점이 있다.
- Consistuency ( = phrase structure grammar = context-free grammars (CFGs))
- Dependency
Consistuency
이 방법은 word를 모아서 하나의 phrase가 되고, phrase가 모여 bigger phrase가 되는 것처럼 단어들의 구조를 본다. 품사등을 적극적으로 활용한다.

Dependency
Dependency structure는 단어들이 어디에 의존적인지를 기준으로 구조를 본다. 예를 들어 Look in the large crate in the kitchen by the door에서 crate는 Look에 의존적이다.
단어 자체가 어느 문맥에 있느냐에 따라서 매우 모호해질 수 있다. 따라서 정확하게 해석하기 위해서 이러한 구조를 필요로 한다. 예를 들어 San Jose cops kill man with knife는 경찰이 칼로 남자를 살해하였다는 말이 될 수도, 칼을 든 남자를 살해하였다는 말이 될 수도 있다.
추가적으로 더 살펴보고 싶으면 “Erkan et al. EMNLP 07, Fundel et al. 2007, etc.”를 살펴보자
Dependency Grammar and Treebanks
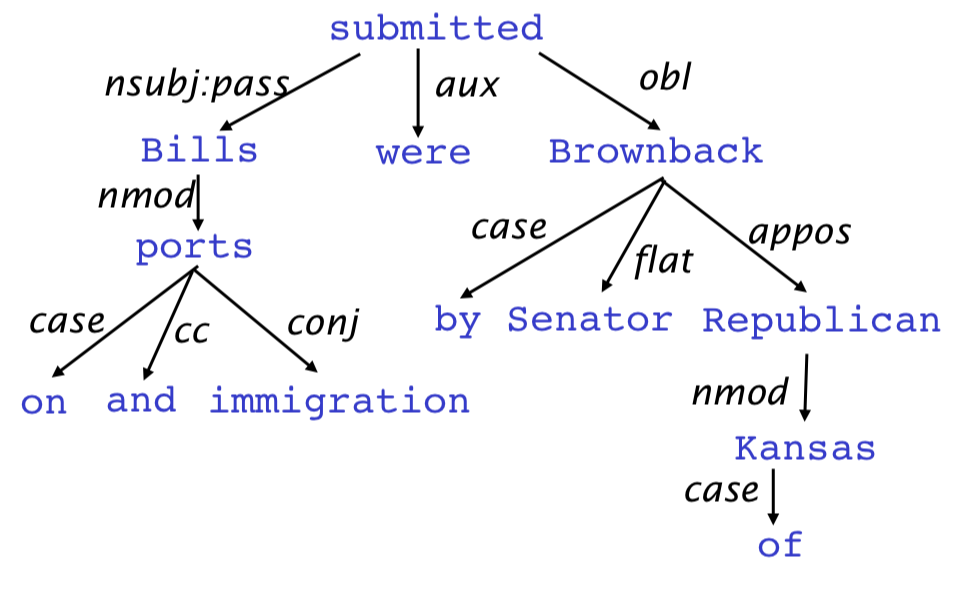
dependency는 tree representation을 이용한다.
- dependency는 binary asymmetric arrow로 나타낸다.
- 이 arrow들은 보통 typed이며, 문법적인 관계이다.
- 보통 fake ROOT를 추가한다.
이런 dependency structure는 기원전 5세기부터 내려오는 아이디어이고, Constituency/context-free grammar는 상당히 최근의 20세기즈음부터 쓰이기 시작한 방법이다.
최근 중요한 툴로 사용되고 있는 Treebank에 대해서는 “Universal Dependencies: http://universaldependencies.org/ ; cf. Marcus et al. 1993, The Penn Treebank, Computational Linguistics”를 참고하자. Universal Dependencies에 들어가보면, 한국어에 대한 데이터도 존재한다. KAIST Korean Universal Dependency Treebank
Dependency Parsing은 몇가지 제한/preference가 존재한다. 지금은 “fake ROOT를 무조건 추가해야한다!” “순환하게 만들지 않는다.” 등이 있고, 더 고려할 것으로 “non-projective하게 만든다.” 정도가 있다. 여기서 projective한 것은 문장의 단어들이 순차적으로 놓여있을 때 dependency arrow가 다른 arrow를 교차하지 않는 것이다.
여튼 넘어가서 Dependency Parsing의 방법들은 아래같은 방법들이 있다.
- Dynamic programming
- Graph algorithms
- Constraint Satisfaction
- “Transition-based parsing” or “deterministic dependency parsing”
- Greedy한 방법과 ml classifier의 조합(MaltParser, Nivre et al. 2008)으로 좋은 성능을 보였다.
Transition-based dependency parsing
stack, buffer, dependency arcs로 구성되어 있다.

Neural dependency parsing
왜 NN Parser를 쓰나면, 속도가 너무 차이가 난다. (Chen and Manning 2014를 참고해보자) MaltParser가 초당 469개의 문장을 파싱하는데, NN 기반의 파서(C & M 2014)가 초당 654개의 문장을 파싱했다.