CS224n Lecture 18 Constituency Parsing and Tree Recursive Neural Networks
18강이고 강의 전체가 다 끝나기까지 이 강의를 제외하고 2강정도만 남았다.
Last Minute Project Tips
이건 파이널 프로젝트 팁인데, 느리고 아무것도 동작안하면 처음으로 그냥 맘편히 돌아가서 다시 해보는 것이 좋다고. 패닉인 상황일테니까. 디버깅을 위해 매우 작은 네트워크랑 데이터를 넣어보기도 하고, 잘 동작하면 모델 사이즈를 키워보기도 하라고 한다.
Motivation: Compositionality and Recursion
- semantic 정보를 우리가 잘 가져갈 수 있을까?
- word embedding만으로 충분할까?
- 만약 잘 가져갈 수 있다고 해도, 정말 큰 phrase에 대해서는?
위의 문제 때문에 compositionality를 생각하게 되었고, 단어, 구들의 semantic composition을 구성하자는 아이디어가 나왔다.

그럼 tree 형태로 구성하기 위해서 recursive한지 물어본다면 논쟁이 있을 수 있겠지만, language 자체를 표현하는데 엄청 자연스럽다고.
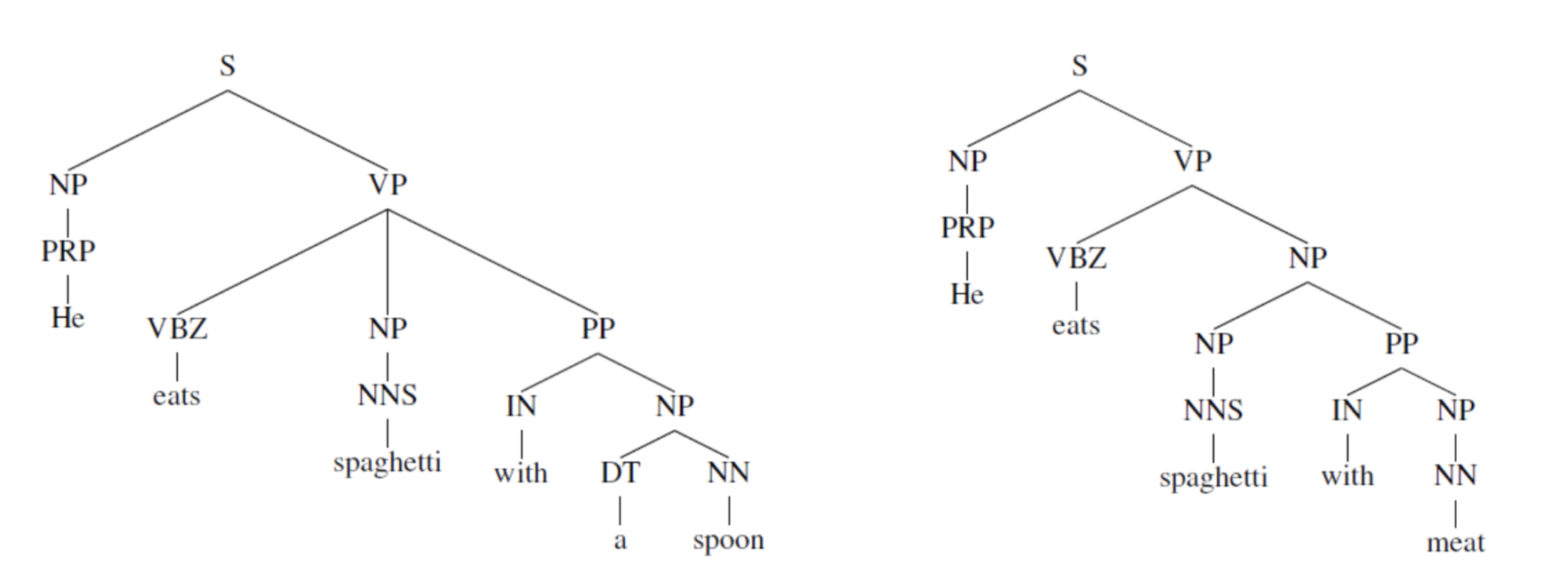
Structure prediction with simple Tree RNN: Parsing
vector space에 word vector를 뿌려놓는데, 그럼 구들은 어떻게 해야하나?? -> 그냥 바로 같은 vector space에 넣어버리자. 그럼 어떻게 phrase의 embedding을 결정할까??
- 단어의 의미들과
- 그들을 combine하는 규칙을 만들어서!
위의 경우는 recursive한 경우이고, 일반적인 rnn을 통해서도 결과는 다르겠지만 구해볼 수 있다. 하지만 recursive한 구조는 tree structure를 구성해주어야 한다는 어려움이 따르고, rnn을 통한 구조는 phrase를 prefix context없이 잡아내지도 못하고, 마지막 결과 vector가 마지막 단어에 좌우된다는 단점이 있다.
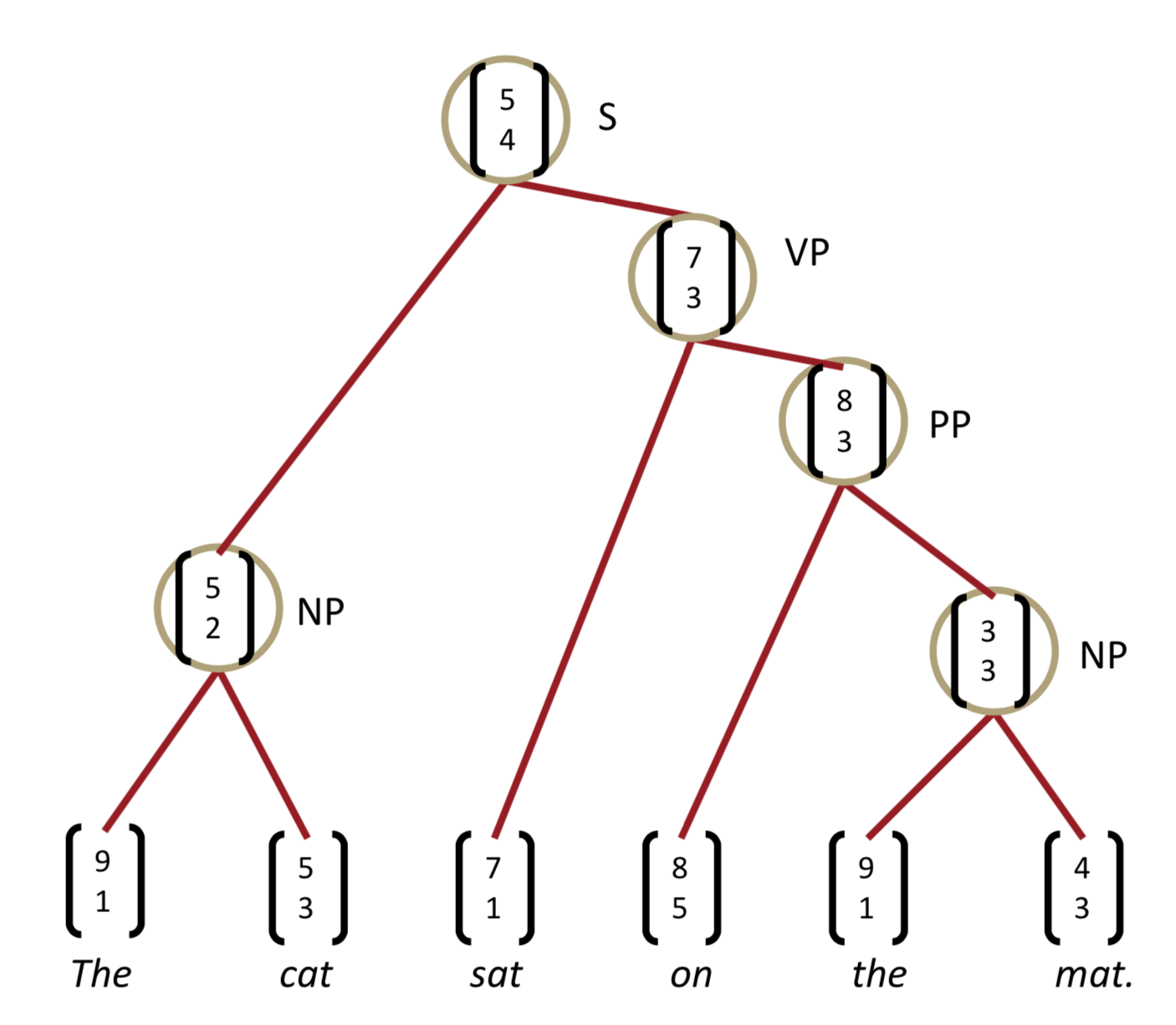
그럼 NN에 어떻게 structure prediction을 할 수 있을까? 이렇게 children을 넣고 semantic representation을 뽑아내고, 얼마나 plausible한지(얼마나 Network가 이 노드를 확신하는지 정도..?)도 뽑아낸다. 그런 NN을 모든 children 대상으로 쭉 돌린다음에 그 위의 층에서도 또 돌리고, 또 돌리고 한다고 하는데, 내가 다시 이 글을 봐도 이해 못할 듯 하니 아래 사진을 보자.
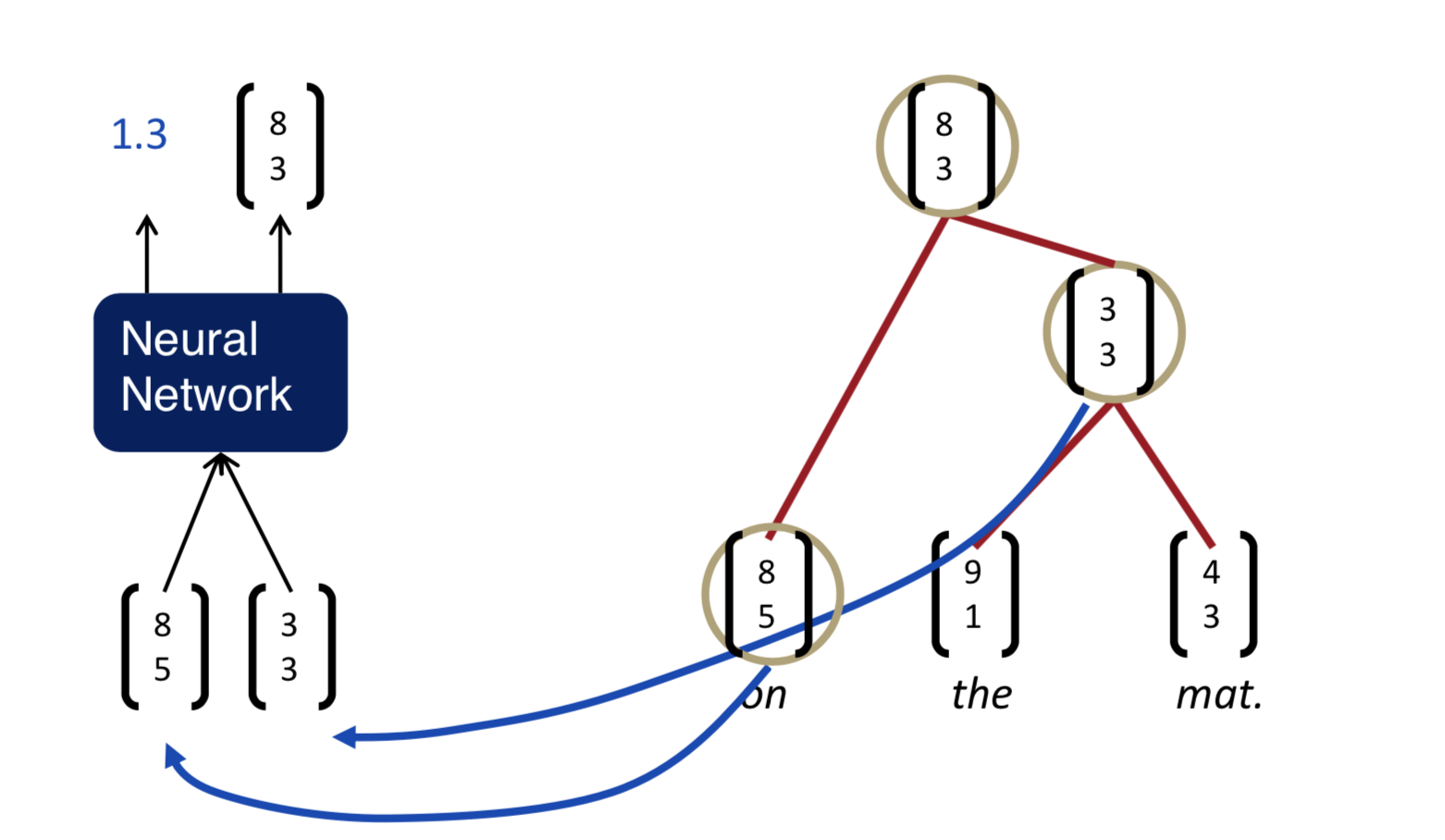

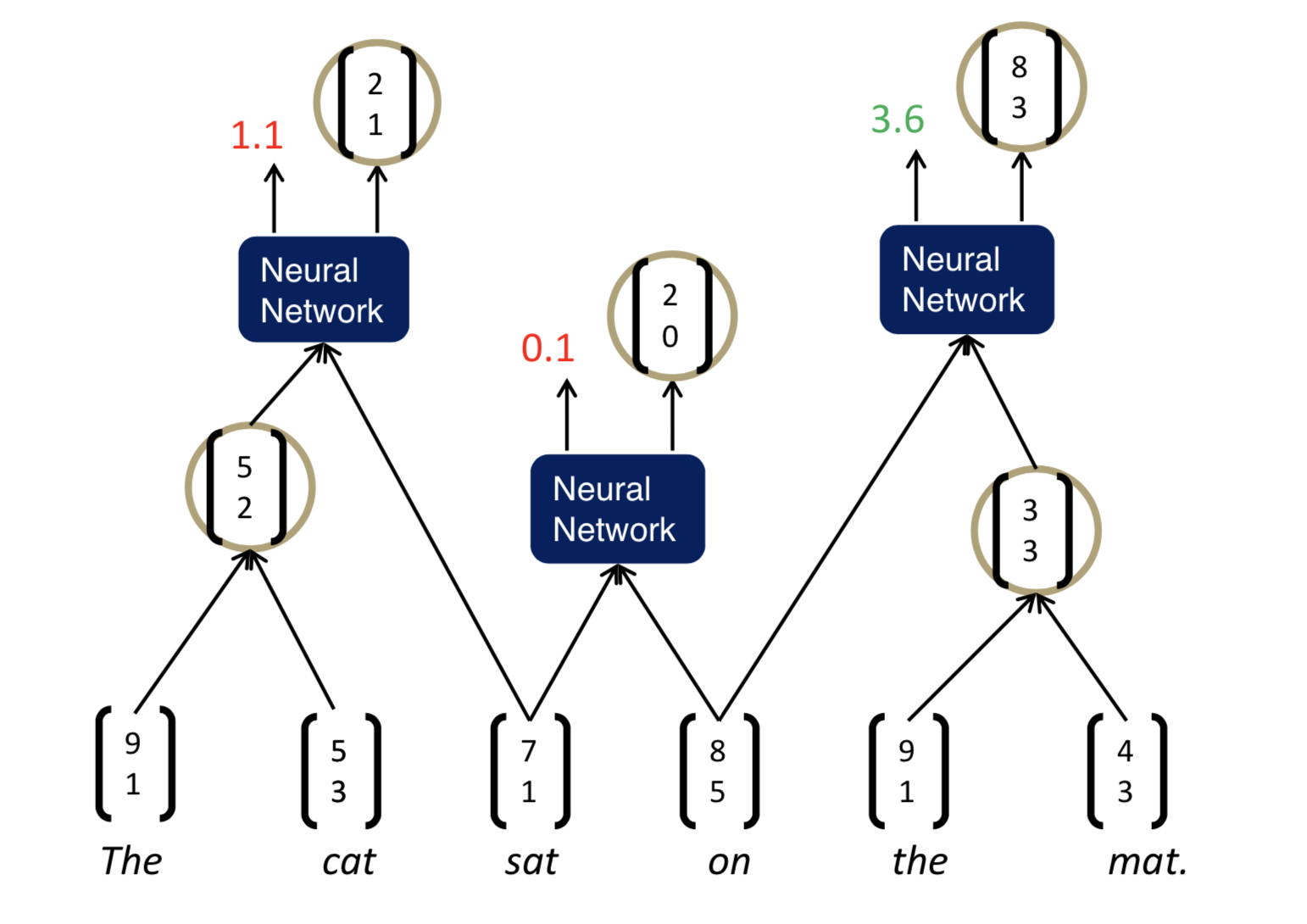
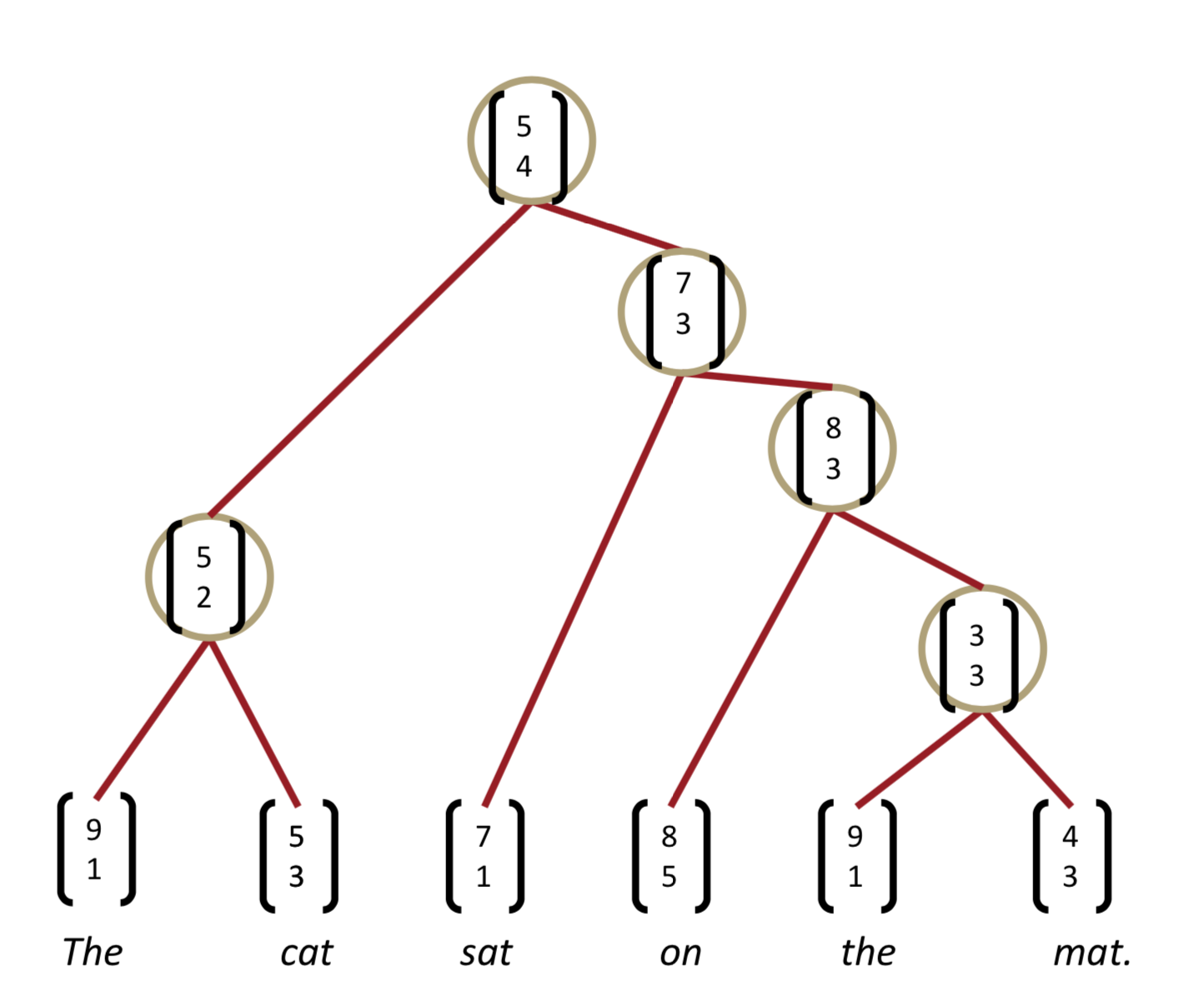
Backpropagation through Structure
general backprop과 크게 다를 것은 없다. 원칙적으로는 같다. Goller & Küchler (1996)에 의해 소개되었다.
forward prop일 때, children \(c_1\), \(c_2\)가 있다고 하자. 거기서 parent \(p\)를 뽑아내기 위해 \(p = \tanh (W \pmatrix {c_1 \\ c_2} + b)\)와 같은 연산을 한다. 그럼 backward prop은 반대로 각각의 노드별로 연산을 해준다. 이런 Simple TreeRNN에 대해서 아래와 같은 점을 생각해볼 수 있다.
- 생각보다 결과는 나쁘지 않고
- 좀 phrase를 잡아낼 수는 있는데, more higher order composition, more complex한 long sentence를 파싱하는데 어려움이 있다.
- input word들 사이의 interaction은 하나도 없다.
- composition function이 다 똑같다
More complex TreeRNN units
두번째로 Syntactically-United RNN이 있는데, Socher, Bauer, Manning, Ng 2013을 살펴보자.
기본적인 syntactic structure를 위해서는 symbolic Context-Free Grammar (CFG) backbone이 좋았다고 한다. 그리고 discrete syntactic category를 사용했다고 하고, 다른 syntactic environment에서는 다른 composition matrix를 사용하게 해주는 것이 훨씬 좋은 결과를 내었다고 한다. 그리고 더 좋은 semantic의 결과를 볼 수 있었다고.
아직 위의 논문을 읽어보지 않아서 자세한 내용을 모르지만, 강의의 내용대로 써보자면, Compositional Vector Grammar를 이용하는 것의 단점이 일단 문제점이 속도가 느리다고 한다. Beam Search 과정에서 matrix-vector product를 하니 연산량이 많아질 수 밖에 없다고. 그래서 subset of tree를 먼저 계산해보고 very unlikely candidates를 미리 없애는 방법(PCFG)을 사용했다고 한다. 그래서 CVG = PCFG + TreeRNN

세번째로 “Semantic Compositionality through Recursive Matrix-Vector Spaces”라는 제목의 논문을 통해 소개된 모델도 소개한다. 원래는 weight matrix \(W\)를 굉장히 적극적으로 이용했는데, word는 대부분 operator처럼 행동하므로, (very good의 very 처럼) composition function으로 처리하자는 것이다.

matrix meaning과 vector meaning으로 나누어 이해하자는 것인데, \(A\)가 matrix meaning, \(a\)가 vector meaning이다. 이걸 결합될 단어랑 연산을 한번 한 다음에 composition function으로 넘긴다. 왼쪽은 vector meaning of phrase를 계산하는 것이고 오른쪽은 matrix meaning of phrase를 계산하는 것이다.

전통적인 방법에 비해 엄청난 향상을 이루었고, 일반적인 RNN에 비해서도 좋은 성능을 보인다. feature를 더 넣게 된다면 더 좋은 성능을 기대할 수 있을 것이라고 말했다.
하지만 여기서 멈추지 않고 문제점을 짚어보자면,
- matrix와 vector를 같이 이용하게 되면서 엄청난 수의 파라미터가 필요했고
- 꽤나 큰 phrase에 대해서 matrix meaining을 잡아낼 좋은 방법이 없었다.
그래서 네번째로 그 다음해에 “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”라는 논문으로 MV RNN보다 parameter수를 줄인 모델을 공개했다고 한다. Recursion Neural Tensor Network라 RNTN이라고 부르는 것 같다.
그 전에 sentiment detection에 대해 한번 짚고 넘어가자면, 일반적으로 sentiment analysis는 단어들을 잘 뽑아내는 것으로 잘 동작한다고 한다. 긴 document에 대해서도 detection accuracy는 90% 수준으로 높다. 하지만, the movie should have been funnier and more entertaining같은 문장은 negative meaning이지만, funnier, entertaining과 같은 단어들만 본다면 positive하게 분류할 가능성이 있다.
위와 같은 문제는 MV-RNN에서도 충분히 잘 동작했고, treebank처럼 좋은 데이터셋을 넣어줄 경우 더 높은 성능을 보였지만, hard negation과 같은 문장들은 여전히 부정확했고, 더 좋은 모델이 필요했다.
attention을 뽑을 때 1 x n, n x n, n x 1의 vector 두개 (주로 단어들의 vector)와 matrix 하나를 중간에 끼워서 쓰는데, 이걸 다르게 생각해서 matrix말고 3-dim tensor를 끼워서 쓰자는 것이다. 그래서 많은 정보를 잘 interact해서 잡아내도록 하자는 것이다.

sentence labels 데이터셋에서는 잘 성능이 안나왔지만, treebank에서 나머지들보다 좋은 성능으로 잘 나왔고, negation이 특히 잘 되었다.
Other uses of tree-recursive neural nets
다른 것에 대한 소개로 QCD-Aware Recursive Neural Networks for Jet Physics에 대한 소개도 있는데, 이건 물리쪽 분야로 적용한 것이라 간단하게 스킵
그 다음 굉장히 재밌어보이는 것은 Tree-to-tree Neural Networks for Program Translation으로 CoffeeScript를 JavaScript로 변환하는 모델을 작성한 것이다.