CS224n Lecture 15 Natural Language Generation
LNG에 대한 Neural Approach에 대한 방법을 15강에서 강의한다고 한다. 슬라이드는 여기로.
- LNG에 대한 기본적인 사항들을 알려주고
- decoding algorithm에 대해 말하며
- NLG task와 해당 task를 위한 neural approach를 알려주고
- NLG는 어떻게 evaluation을 진행하는지,
- NLG research와 현재 트렌드, 그리고 미래는 어떤지
에 대해서 말해준대요.
Recap: LMs and decoding algorithms
NLG
NLG는 새로운 text를 만들어내는 작업이고, 아래와 같은 것들의 subcomponent가 될 수 있다.
- Machine Translation
- (Abstractive) Summarization
- Dialogue (chit-chat and task-based) -> 이건 아마 일상대화인듯한데..?
- Creative writing: storytelling, poetry-generation
- Freeform Question Answering -> 답변을 그냥 생성
- Image captioning
LM
LM은 next word를 predicting하는 task였고, \(P(y_t \vert y_1,...,y_{t-1})\)의 확률 분포를 뱉어낸다. 그리고 RNN을 이용하면 RNN-LM이다.
conditional LM이라는 것도 있는데, 이거는 x라는 input이 올 때까지 고려한다. 즉, \(P(y_t \vert y_1, ..., y_{t - 1}, x)\)가 되는 것이다. 이게 특별하게 생각하기 보다, 전체 텍스트 x에 대해 y로 summarize하는 것을 생각하면 될 것 같다.

Decoding Algorithm
conditional LM을 학습하고 나면 이것을 어떻게 NLG에 활용할 것인가?? -> decoding algorithm을 통해 할 수 있다. 이 전에 Greedy Decoding과 Beam Search 내용을 배웠었고, 각각의 내용은 아래와 같다.
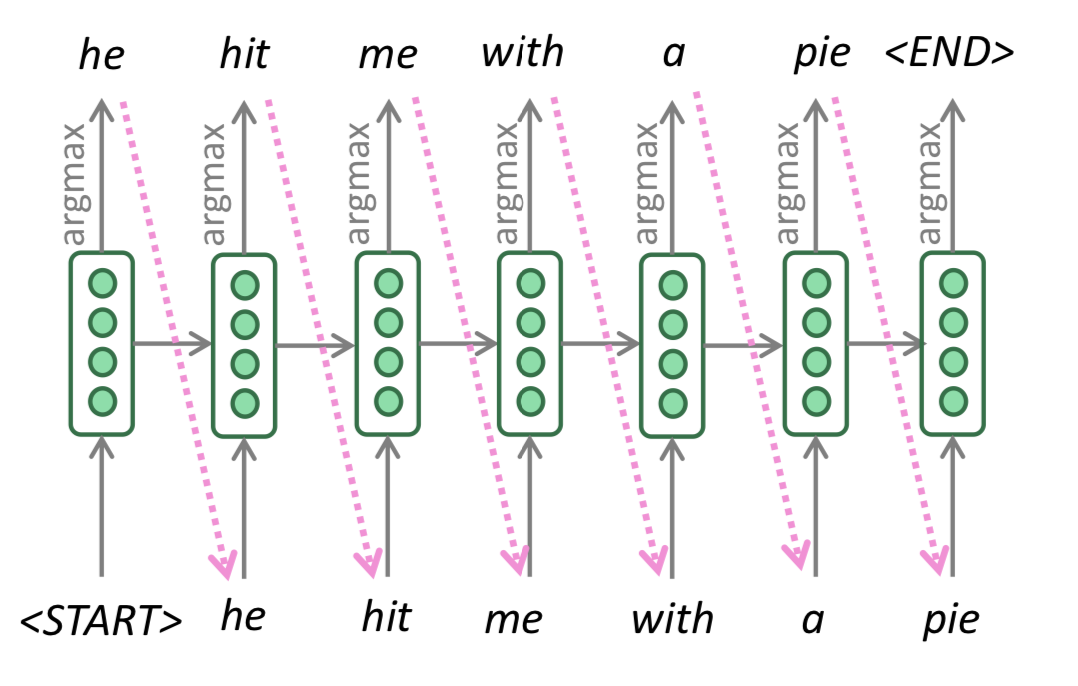
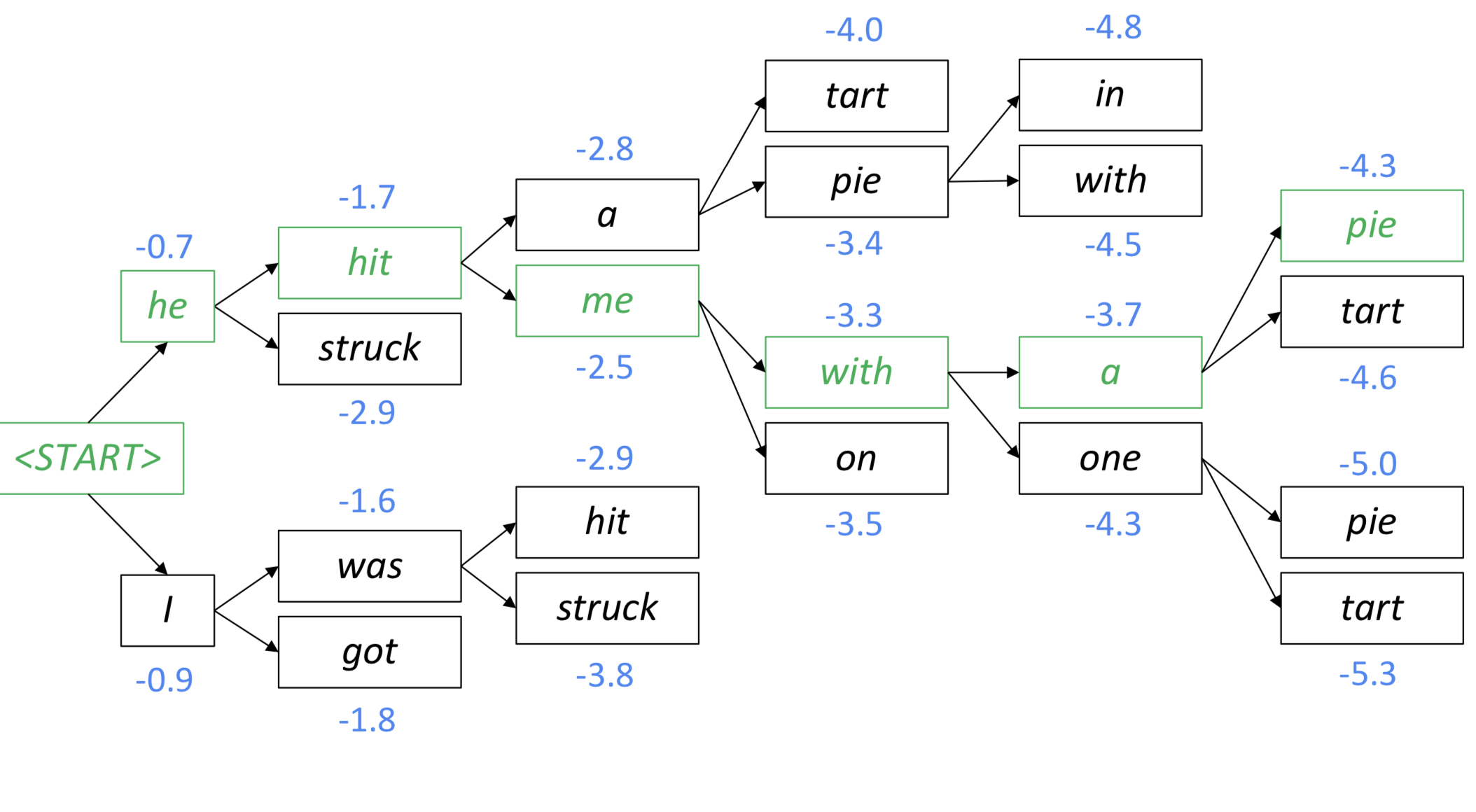
Beam Search
Greedy Search에서는 어차피 그 상황에서 가장 확률이 높은 것만 고른다지만, Beam Search는 beam size라는 hyper parameter가 하나 더 있으므로, “beam size를 어떻게 고를 것인가?”를 골라야 한다.
beam size가 작으면, Greedy Search와 거의 같아진다. (beam size가 1인 beam search가 greedy search이니…) beam search가 크면, computationally expensive하다. 또 너무 크면 NMT에서 BLEU score를 떨어뜨릴 수 있다. (이게 short translation을 찾아내기 때문이라고) 그리고 일상대화 (chit chat) 분야에서는 generic하게만 답변을 낼 수도 있다.
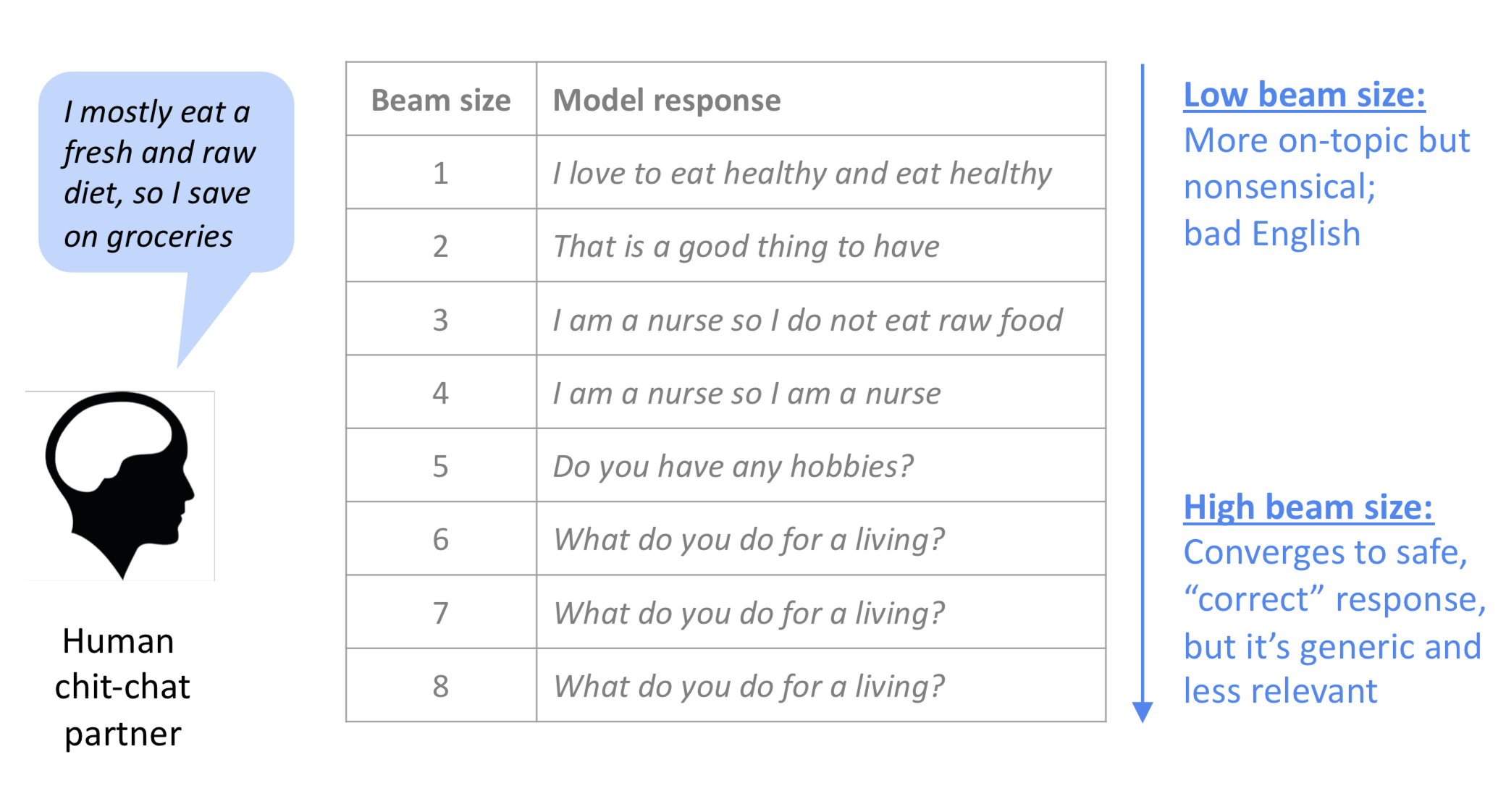
Sampling based decoding
이건 처음 나오는데, 다음 단어를 골라낼 때, step t에서 확률 분포 \(P_t\)로부터 랜덤하게 샘플링한다고 한다. Greedy decoding처럼 하지만, argmax가 아니라 sampling을 사용한다고.
하지만 너무 랜덤하게 샘플링하면 문제가 있을 수 있으니 top-n의 단어로 제한하여 샘플링 하는 방법도 사용한다. (top-n sampling) 여기서도 top-n의 n을 1로 두면 Greedy Search와 같아진다. Beam Search처럼 hyper parameter를 고르는 것은 중요한데, 여기서는 n에 해당한다. n이 커지면 diverse하고 risky한 결과를 내는데 반해 n을 줄이면 generic하고 safe한 결과를 낸다.
Softmax Temperature
step t에서, LM이 softmax function을 score들의 vector인 \(s \in \mathbb R^{\vert V \vert}\)에 적용하여 \(P_t\)의 확률 분포를 계산한다고 한다. 말만 들어서는 저도 뭔지 모르겠고 식은 아래와 같다.
\[P_t (w) = \frac {\exp(\frac {s_w} \tau)} {\sum _{w^\prime \in V} \exp(\frac {s_{w^\prime}} {\tau})}\]이게 \(\tau\)는 temperature hyperparameter이고, 적용해도 되고 안해도 되는 값인가 본데 이걸 늘리면 \(P_t\)를 더 uniform하게 만들고 output을 더 diverse하게 만들 수 있다고 한다. 즉, 확률 분포가 단어 전체에 고루 퍼진다. 반대로 줄이면, 확률 분포가 더 spiky하게 되고, output은 몇몇개의 단어에만 집중하게 된다고 한다.
근데!!! 이 softmax tempaerature는 수식을 보면 알겠지만, decoding algorithm은 아니고, decoding algorithm과 함께 쓴다.
NLG Tasks and Neural Approach to them
Summarization
summarization은 input text x에대해 summary y를 만들어내는 태스크이다. Summarization은 single document에 관한 것일 수도 있고, multi document에 관한 것일 수도 있다. summarization에 관해 실제 코드/데이터셋을 참고해보고 싶다면 GitHub - mathsyouth/awesome-text-summarization을 참고하자. (역시 awesome-**)
summarization은 두가지 방식이 있는데, Extractive summarization과 Abstractive summarization이다. 전자는 중요한 부분을 골라내는 것이고, 후자는 새로운 텍스트를 아예 만들어낸다.
Pre Neural Summarization
Pre-Neural Summarization에 대해 말해준다. mostly extractive하고, MT처럼 pipeline이 있는데, Content Selection을 하고 Information Ordering을 한 후 Sentence Realization을 한다. 이를 위해서 각각의 문장에 대해 점수를 매기는 과정이 필요한데, 이것은 topic이 해당 문장에 존재하는지 등을 보고 계산한다고 한다. 아니면 문장의 위치라던가..?
Evaluation: ROUGE (Recall-Oriented Understudy for Gisting Evaluation)

BLEU처럼 ngram base인데, 다른 점은 문장이 짧다고 패널티를 주진 않는다는 점이다. 그리고 ROUGE는 recall에 기반하고, BLEU는 precision에 기반한다. 각각의 어떤 문제를 풀고자 하는지에 따라 선택한거라 보면 될 것 같다. 근데, F1 version of ROUGE도 자주 쓰인다.
Neural Summarization
처음은 single-document abstractive summarization을 translation task로 보고 seq2seq로 풀어봐도 좋지 않을까? 하는 생각에 2015년에 seq2seq + attention을 적용한 관련 논문이 나왔다고 한다. 1 최근에는 Hierarchical / multi-level attention을 적용하기도 하고, global contents에 대해 처리하기, high-level content selection에 대해 신경쓰기도 한다고 한다. 그리고 pre-neural summarization에서 나온 아이디어를 같이 적용하기도 한다고. ROUGE라는 score가 있으니 RL도 시도한다고 한다.
근데 이게 문제점이, seq2seq + attention에 의존하면 말은 잘 나오지만, 디테일을 잘 잡아내지 못한다고 한다. 그래서 Copy Mechanism을 seq2seq와 함께 사용해서 그런 것을 잡아낸다고 하는데, 강의에서 설명하는 방식은 각각의 decoding 과정에서 \(p_{gen}\)을 미리 계산한 후 Context Vector랑 Attention Distribution이랑 잘 섞어서 generation distribution과 copying distribution을 계산해 낸 후 그걸 토대로 \(P(w)\)를 만들어낸다고 한다.
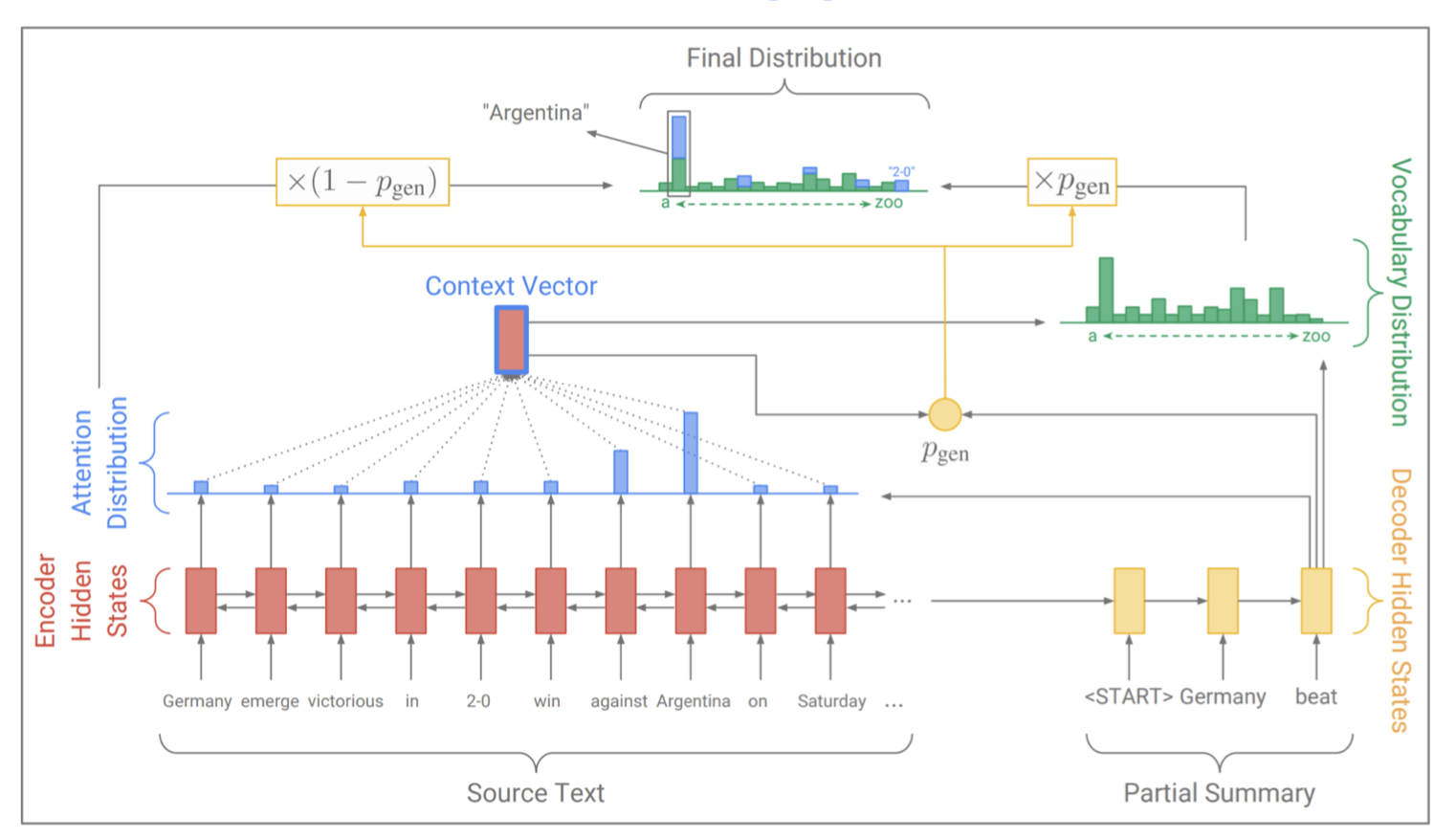
하지만 Copy Mechanism도 문제가 있는데, 너무 많이 copy한다는 점과 input document가 너무 길다면 content selection 성능이 너무 떨어진다는 점이다.
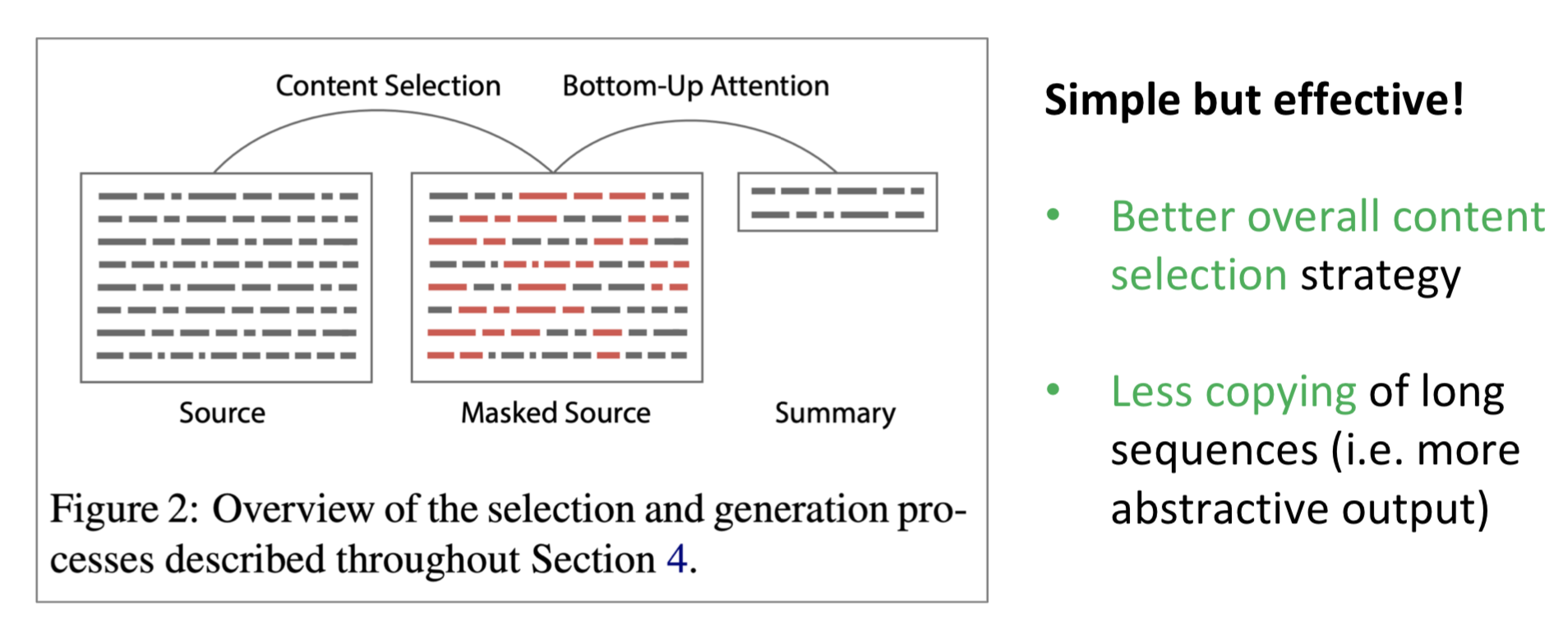
Bottom up summarization
기존의 pre-neural summarization은 content selection과 surface realization으로 나누어진다. 하지만, neural approach는 그런 것없이 하나로 묶여서 나오기 때문에 global content selection strategy가 부족할 수 밖에 없다. 그래서 bottom-up summarization을 하자!
neural sequence tagging model을 사용해서 포함할 단어와 포함하지 않을 단어를 우선 선택한다. 그리고나서 seq2seq + attention으로 처리한다.2
Neural summarization via RL
ROUGE-L을 optimize하기 위해 바로 RL을 사용하자. 근데 이게 어찌보면 당연할 정도로 ROUGE score는 높게 나왔다. 하지만, human judgement score는 낮게 나왔다.
Dialogue
대략 아래같은 종류가 있다.
- Task oriented dialogue
- assistive
- co-operative
- adversarial
- social
- chit-chat
seq2seq based dialogue
dialogue를 text summarization 문제에서도 핫했던 seq2seq로 풀고자 했는데 아래정도의 문제가 나타났다.
- genericness / boring responses
- beam search에서 rare words를 upweight한다.
- irrelevant responses
- input과 response 사이에 maximum mutual information을 optimize하도록 해서 관련있게 만들자
- repetition
- beam search에서 바로 n-gram 반복되는 것을 막아버린다.
- lack of context
- lack of consistent persona
Storytelling
이거 재밌어 보여서 관련 미디움 글 링크 저장!
이미지로부터 storytelling같은 paragraph를 만들어내는 것이 목표이다.
근데 이게 너무 양이 많은지 엄청 건너뛴다. 자세한건 슬라이드 참고
NLG Evaluation
word overlap based metrics 들이 있다. 하지만 이런 것들은 machine translation과 같은 태스크에 적절하지 않고, summarization이나 dialogue엔 오히려 안좋을 수 있다고 한다.
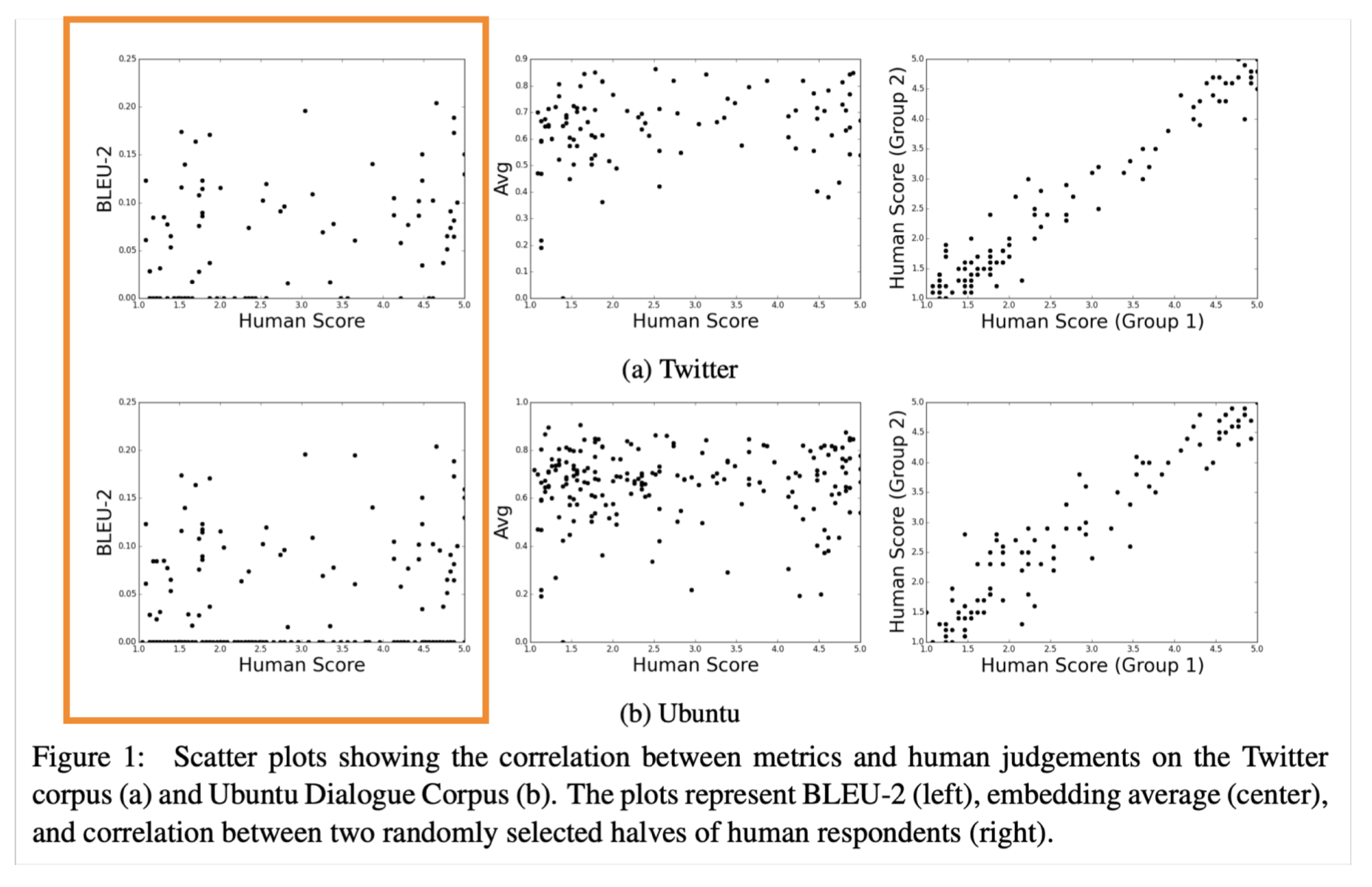
그럼 perplexity는 어떨까? LM만 관련해서는 괜찮을텐데, generation은 영향을 안받는다. word embedding based metrics은 human judgement와 별 관련이 없을 수 있다는 것이다.
그리고 전체적으로 적절한 metrics이 없다. 하지만 특정 태스크에 도움이 될 수 있는 metric은 충분히 있기 때문에 잘 골라쓰는 게 좋을 것 같다.
근데 그렇다고 human judgement는 무조건 좋은가?는 또 아니다. 비싸고 느리고 일관적이지 않을 수 있다.
-
https://arxiv.org/abs/1509.00685 이 논문을 참고해보자 ↩
-
https://arxiv.org/abs/1808.10792 이것도 참고해보자 ↩