CS224n Lecture 13 Modeling contexts of use: Contextual Representations and Pretraining
13강 정리! 11강부터인가? 그때부터 대부분 소개가 되어가고 있어서 좋은 링크 정리 정도만 하고 있는 것 같다.
Reflections on word representation
지금까지는 word embedding을 시작부터 했는데, pretrained model를 사용하자는 말. 그 이유는 더 많은 단어와 더 많은 데이터에 대해 학습이 가능해진다는 이유이다. 실제로 성능도 더 높은 것으로 보인다.
근데 unknown words에 대해서는 어떻게 대응할 것인가? UNK으로 매핑해서 어쩌구저쩌구를 하지만 결론은 char-level model을 사용하자! 또는 테스트때 <UNK>가 unsupervised word embedding에 존재한다면 그걸 계속 쓰고, 그냥 아예 모르는 것은 random vector로 만든다음에 vocab에 추가하는 방법도 고려해보라고 한다. 1
어찌되었든 word embedding을 시작부터 학습시키는 것은 두가지 큰 문제가 있는데, 하나의 단어에 대해 context 상관없이 다 같은 representation을 가져온다는 점이다.
이 문제에 대한 해결법은 무엇일까? NLM에서 LSTM Layer들은 다음 단어를 예측하기 위한 모델이다. 그 말은 context-specific word representation을 만들어낼 수 있다는 말이 아닐까?
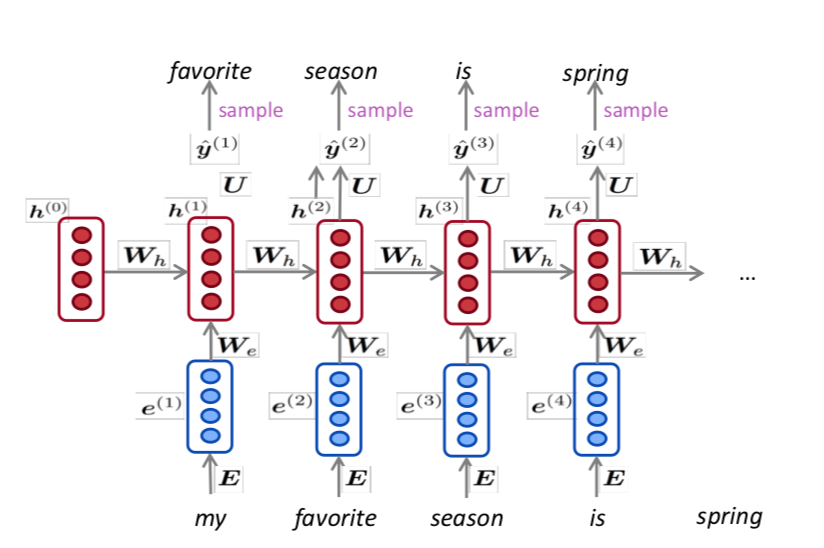
Pre-ELMo and ELMO
TagLM2이란 논문은 ELMo가 나오기 전에 나온 논문이다. 메인 아이디어는 word representation을 context안에서 해내고 싶지만, 그렇게 기존의 학습방식과 다르지 않게 하고 싶다는 것이다. 그래서 semi-supervised approach 방식을 차용하였다. 이게 Pre-ELMo
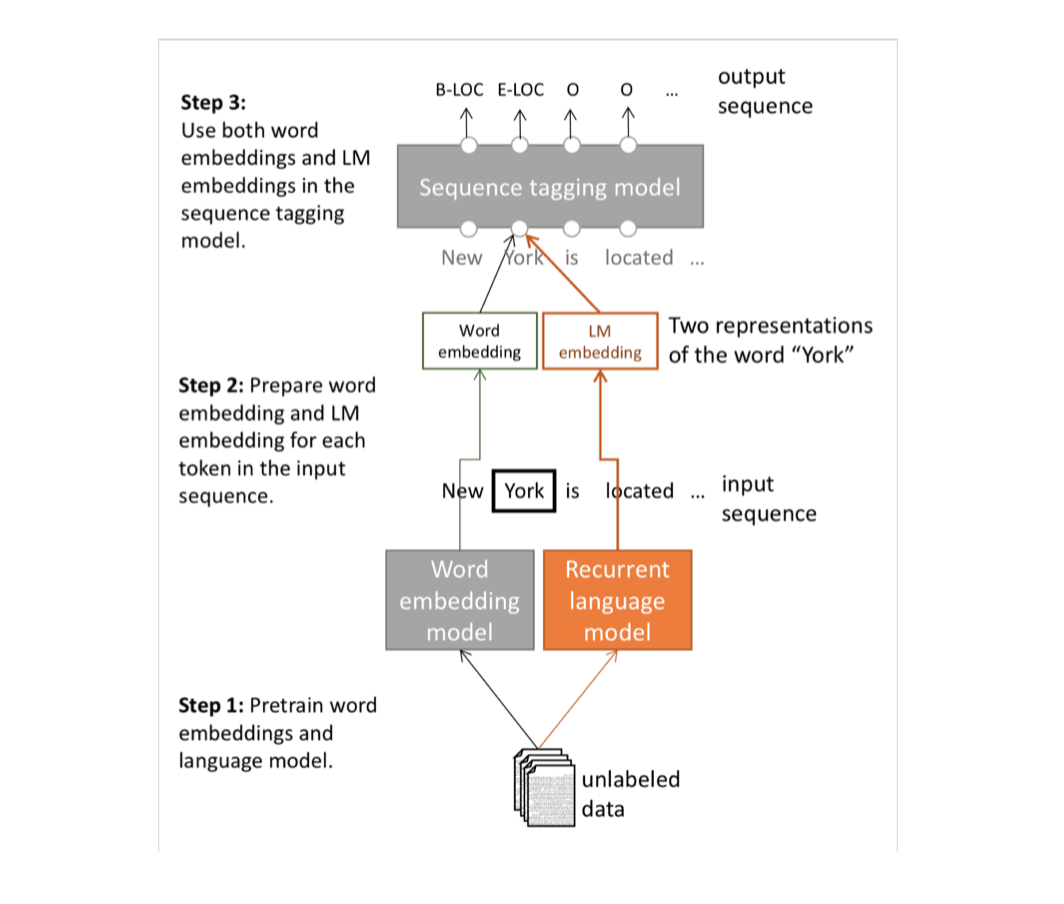
CoVe라는 모델도 있었는데, 이건 그냥 강의에서 넘어감
ELMO는 Deep Contextualized word representations라는 제목을 가진 논문의 모델이다. word token vector와 contextual word vector의 breakout version이다. word token vector를 long context로부터 배운다. (다른 모델들은 fixed window context로부터 배우나..?)
bi-drectional LM을 사용하지만, 성능때문에 이상할 정도로 큰 LM을 사용하진 않는다. 두개의 biLSTM layer로 구현했다고 한다. 또한 initial word representation을 위해 character CNN을 사용했다고 하고, redisual connection도 사용했다고 한다. 자세한 사항은 논문을 읽어보아야 알 수 있을 것 같다.
ULMfit and onward
ULMfit: Universal Language Model 3
어떻게 NLM Knowledge를 공유하여 사용할 수 있나가 핵심. text classification을 예시로 강의에서는 설명한다. ULMfit은 reasonable-size여서 더 알려진 점도 있는 것으로 보인다. 1GPU로 학습이 가능했다고 한다. transfer learning 같은 키워드를 같이 찾아보자.
ULMfit 이후로 점점 계속 큰모델이 많이 나온다. OpenAI에서 만든 2048개의 TPU를 사용하는 GPT-2 모델은 꽤 좋은 성능을 낸다고.
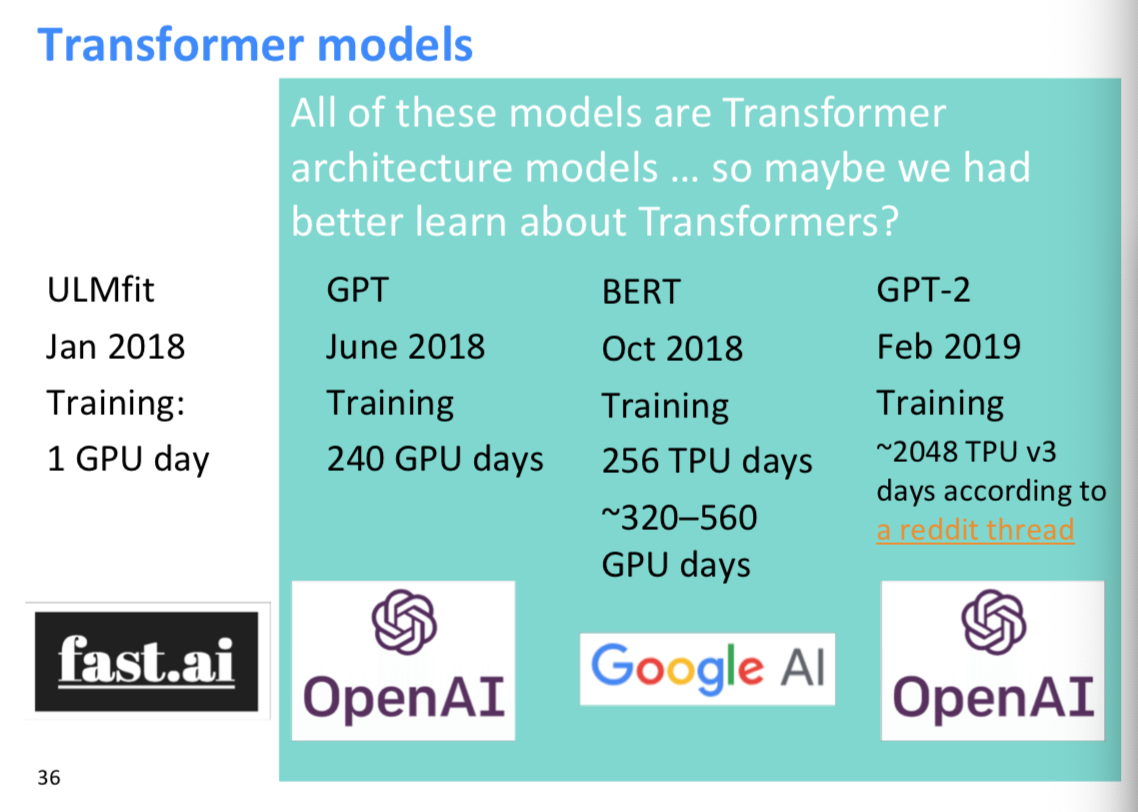
근데 큰 모델들은 전부 Transformer다.
Transformer architecture
Motivation
우린 RNN 연산을 parallelization하고 싶다. 근데 long range dependencies는 그대로 필요하다. 그를 위해 Recurrant Model에서는 Attention을 사용하고 있었고, attention이 해당 dependency를 알려주니, 그냥 Recurrant Model을 쓰지 않고 attention만 써보는 것은 어떤가?
Overview
Attention is all you need 논문을 보자. 그와 같이 보기를 추천하는 리소스들은 아래정도이다.
논문에서는 Dot Product Attention, Scaled Dot Product Attention, Multi-head attention을 하는데, 논문 읽고도 잘 이해 안되었으니까 논문 정리할때 다시 보자.
아래와 같은 키워드/논문을 찾아보자
- byte-pair encoding
- checkpoint averaging
- adam optimizer
- dropout
- label smoothing
- auto-regressive decoding with beam search and length penalties
BERT
논문은 여기를 보면 된다.
BERT의 핵심 아이디어는 언어는 양방향으로 이해해야 하는데, 왜 한쪽만 볼까?라는 것이다. 따라서 Bidrectional context를 구성했다. 학습은 k%의 단어를 가리고 그 단어들에 대한 prediction을 통해 하게 되었다. 항상 15%를 사용했다고 하는데, k가 높으면 context가 충분하지 않고, k가 너무 적으면 학습하기에는 너무 cost가 높다.
추가로 Next Sentence Prediction 같은 것도 진행하는데, sentence 사이의 relationship을 학습하는 태스크이다. sentence A와 B가 주어지면 IsNextSentence인지, NotNextSentence인지 맞추는 태스크이다.
bert는 transformer encoder를 사용하고 self-attention을 사용하기 때문에 locality bias가 존재하지 않는다. 또한 long distance context도 충분히 고려된다.