Review of "Attention Is All You Need"
Transformer를 소개하는 논문으로, CS224n강의의 suggested readings 목록에 있어서 읽어본 논문이다. 한국어 리뷰도 엄청 많을 정도로 유명한 논문이다. 해당 논문을 읽고, 간략한 정리를 해보았다. 논문은 arXiv:1706.03762에 있다.
Abtract
Transformer는 기존과 다르게 완전히 attention만으로 이루어진 구조이다. 2014 WMT English-to-German translation task에서 sota를 찍은 모델이라고 한다.
1. Introduction & 2. Background
Recurrent Model은 순서가 중요하다는 특성상 병렬화하기가 어렵다. 하지만 이 transformer라는 Attention에 기반한 모델은 input과 output의 global dependency를 바로 뽑아낼 수 있기 때문에 병렬화하기 좋다. 따라서 sota인 모델을 P100 8대로 12시간만에 만들어낼 수 있었다. sequence-aligned RNN없이 완전히 self-attention (intra attention)만 사용하는 모델이다.
3. Model Architecture
3.1 Encoder and Decoder Stack
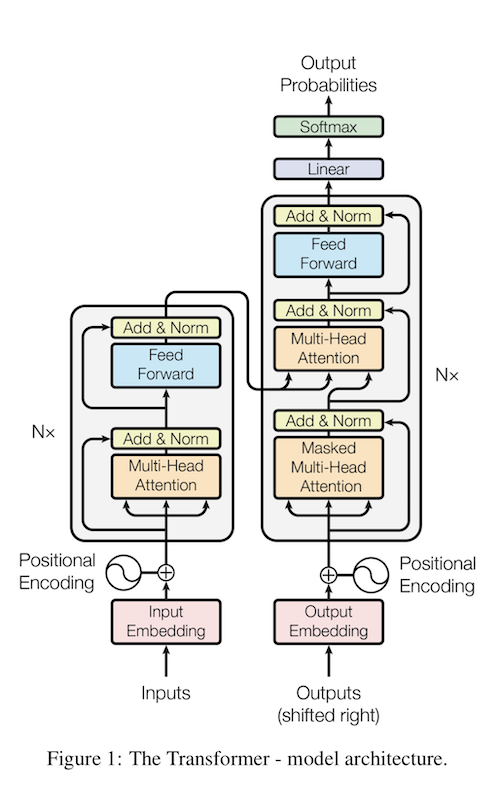
우선 Encoder-decoder structure를 가지고 있다. 하지만 stacked self-attention을 사용하고, point-wise feed forward network를 사용한다.
Encoder
Encoder의 Layer 하나는 두 개의 sublayer로 되어 있으며, 첫번째는 multi-head self-attention mechanism을 가지고 있다. 두번째는 position-wise fully-connected feed-forward network를 사용한다. residual connection을 사용한 것을 그림에서 볼 수 있다. 논문에서 설명하길 하나의 sublayer를 \(\text{LayerNorm}(x + \text{SubLayer}(x))\)로 보라고 한다. 이런 layer 하나를 6개를 쌓았다.
Decoder
Encoder의 두개의 sublayer의 결과값에 multi-head attention을 수행하는 레이어를 연결한다. 역시 또 redsidual connection을 sub layer마다 연결해준다. 그리고 첫 레이어에 일반적인 multi-head attention을 만들어주는 것이 아닌 masked multi-head attention을 만들어준다. 이 masked layer로 인해 position \(i\)에 대해서 prediction을 수행할 때 오로지 \(i\)보다 작은 위치의 결과에 의존한다.
3.2 Attention
attention function은 query와 set of key value pairs를 output으로 mapping하는 function로 생각할 수 있다. 물론 여기서 key, value, query, output은 전부 vector이다.
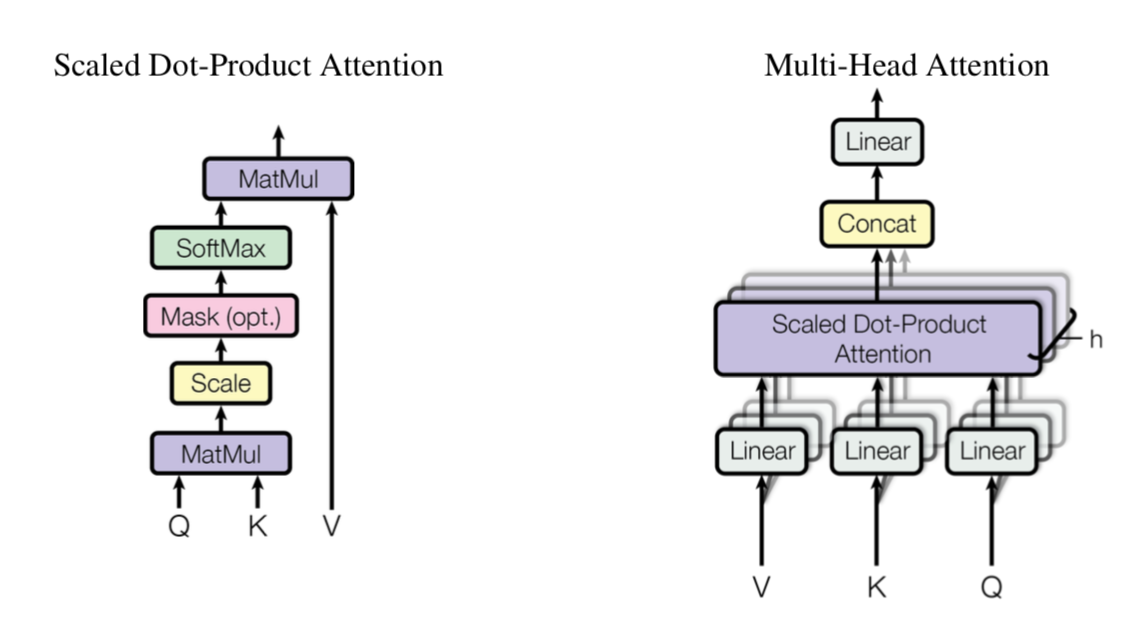
3.2.1 Scaled Dot-Product Attention
이 논문에서 쓰는 Attention 구조 중 하나가 Scale Dot-Product Attention이다. input은 \(d_k\)차원의 query, key이고, \(d_v\) 차원의 value이다. 위 그림을 식으로 바꿔주면 아래처럼 된다.
\[\text{Attention} (Q, K, V) = \text{softmax}(\frac{QK^T} {\sqrt {d_k}})V\]일반적으로 많이 쓰이는 attention함수들은 additive attention1과 dot-product(multiplicative) attention인데, dot-product attention이 위의 식과 \(\sqrt{d_k}\)로 scaling하는 것만 빼면 똑같다고 한다. Additive Attention은 compatibility function을 1개의 hidden network를 가진 feed-forward network를 계산하는데, 이론적으로 dot-product attention과 복잡도는 비슷하지만, dot-product attention이 빠르고 space-efficient하다고 한다. 그 이유는 highly optimized matrix multiplication code를 사용할 수 있으므로.. 그냥 최적화하기 용이하단다.
\(d_k\)가 값이 작다면 additive와 multiplicative는 비슷하게 동작하고, 오히려 additive가 더 좋은 성능을 낸다. 하지만 \(d_k\)가 커도 softmax function이 small gradients를 가진 부분으로 수렴될 수 있으므로, \(\frac 1 {\sqrt {d_k}}\)로 scale했다고 한다.
3.2.2 Multi-Head Attention
각각 key, value, query를 single attention에 넣는 것보다 key, value, query를 전부 project해서 parallel하게 attention function을 수행하는 것이 좋은 것을 발견했다고 한다.
\[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h) W^O \\ \text{where } \text{ head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i)\]구현할 때는 \(h=8\)로 사용했고, \(d_k = d_v = d_{model} / h = 64\)를 사용했다고 한다. 각각의 head가 dimension이 줄었으므로, total computational cost 또한 single head attention을 full dimensionality하게 계산한 것과 비슷하다고.
3.2.3 Applications of Attention in our Model
Transformer는 multi-head attention을 세가지 다른 방식으로 사용한다.
- encoder-decoder attention에서 query는 이전 decoder layer에서, memory key, value는 encoder의 output에서 온다고 한다. 이 방식은 모든 position에서 decoder가 input sequence의 모든 position을 사용할 수 있게 한다. 이건 seq2seq 모델의 encoder-decoder attention mechanism과 닮았다고.
- encoder는 self-attention layer를 포함한다. encoder의 input인 key, value, query는 전부 이전 previous encoder layer의 output에서부터 온다.
- 마찬가지로 decoder의 self attention layer는 각각의 decoder에서 해당 decoder의 position까지의 정보를 전부 사용할 수 있도록 한다. 하지만 auto-regressive한 특성을 위해 leftward information을 잘 다룰 필요성이 있었고, 그래서 illegal connection의 값들을 전부 \(-\infty\)로 masking했다. -> (이 부분은 잘 이해가 가지 않는데 나중에 다시 생각해보자)
3.3 Position-wise Feed-forward networks
그냥 두개의 linear transformation에 ReLU만 잘 요렇게
\[FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\]3.4 Embeddings and Softmax
linear transformation과 softmax를 활용해서 decoder output을 next token probability를 게산한다. 두개의 embedding layer와 pre-softmax linear transformation에 똑같은 weight matrix를 사용했다고 한다.2
3.5 Positional Encoding
sequence의 순서를 활용하게 하기 위해 PE를 사용했다고 한다. positional encoding을 encoder와 decoder 직전에 사용했는데, 식은 아래와 같다.
\[PE(pos, 2i) = \sin(pos / 10000^{2i / d_{model}}) \\ PE(pos, 2i + 1) = \cos(pos / 10000^{2i / d_{model}})\]\(pos\)는 position이고, \(i\)는 dimension이다. sin, cos을 통해 relative position 정보를 학습하길 기대한 것은 \(k\)라는 fixed offset이 있다고 할 때 \(PE_{pos + k}\)는 \(PE_{pos}\)의 linear function으로 나타낼 수 있기 때문이다.
4. Why Self-Attention

여기서는 self-attention layer와 recurrent, convolution layer와 비교를 한다.
총 세가지 기준이 있는데, 하나는 total computational complexity per layer이고, 다른 하나는 parallelized될 수 있는 computation의 양이다. 세번째는 network 상에서 long range dependency의 path length이다. path length가 짧아질수록 long range dependency를 학습하기 훨씬 쉬워진다. (바로 비교할 수 있으니까)
보통의 상황인(sota 모델, byte-pair representation이나 word piece같은) sequence length \(n\)이 representation dimensionality \(d\)보다 작을 때, computational complexity를 비교할 때 self attention은 recurrent layer보다 빠르다. 하지만 이것보다 더 computational complexity를 개선하기 위해서 neighborhood를 size \(r\)만큼만 고려할 수 있도록 제한할 수 있다. 그렇게 된다면 max path length가 \(O(n/r)\)로 늘어나게 되지만, 나중에 해본다고 한다. (나말고 논문에서)
Convolution layer는 보통 recurrent layer보다 computational complexity가 높다고 한다. 하지만, separable convolution3을 사용하면 훨씬 괜찮다고. complexity가 \(O(knd+ nd^2)\)으로 준다고 한다. 여기서 \(k\)는 separable convolution의 factor. \(k = n\)인 상황에서도 separable convolution의 complexity가 self attention + pointwise feedforward layer의 complexity와 같다고.
하지만, self-attention을 사용하면 조금 더 interpretable한 model을 얻을 수 있다. (attention distribution을 뽑아내면 어디에 조금 더 attend한지?를 알 수 있는 것이 그 이유인 듯 싶다)
5. Training
5.1 Training data and batching
WMT 2014 English-German Dataset을 통해 학습했고, sentence는 byte-pair를 통해 encoding되었다.
5.2 Hardware and schedule
8개의 P100을 사용했고, step하나마다 0.4초 정도 걸렸다. 100,000 step을 계산했다고 하니, 12시간이 걸렸다. 따로 큰 모델을 작성해보았을 때는 step이 1.0초 정도 걸렸고, 300,000 step동안 training을 했을 때 3.5일이 걸렸다.
5.3. Optimizer
\(\beta_1 = 0.9, \beta_2 = 0.98, \epsilon = 10^{-9}\)로 Adam을 사용했다. learning rate는 아래처럼 게산했다.
\[lrate = d^{-0.5}_{model} min(step_num^{-0.5}, step_num * warmup_steps^{-1.5})\]\(warmup_steps = 4000\)으로 사용했다. \(warmup_steps\)동안 learning rate가 증가하다가 step number의 inverse square root로 계속 감소한다.
5.4 Regularization
- Residual Dropout: encoder, decoder stack에서 dropout을 embedding의 합과 positional encoding에 적용했다고 한다. \(P_{drop} = 0.1\)을 사용했다.
- Label Smoothing: label smoothing을 \(\epsilon_{ls} = 0.1\)을 사용했다. perplexity가 안좋아지고 unsure한 것들을 학습하지만, BLEU score는 좋아진다.
6. Results
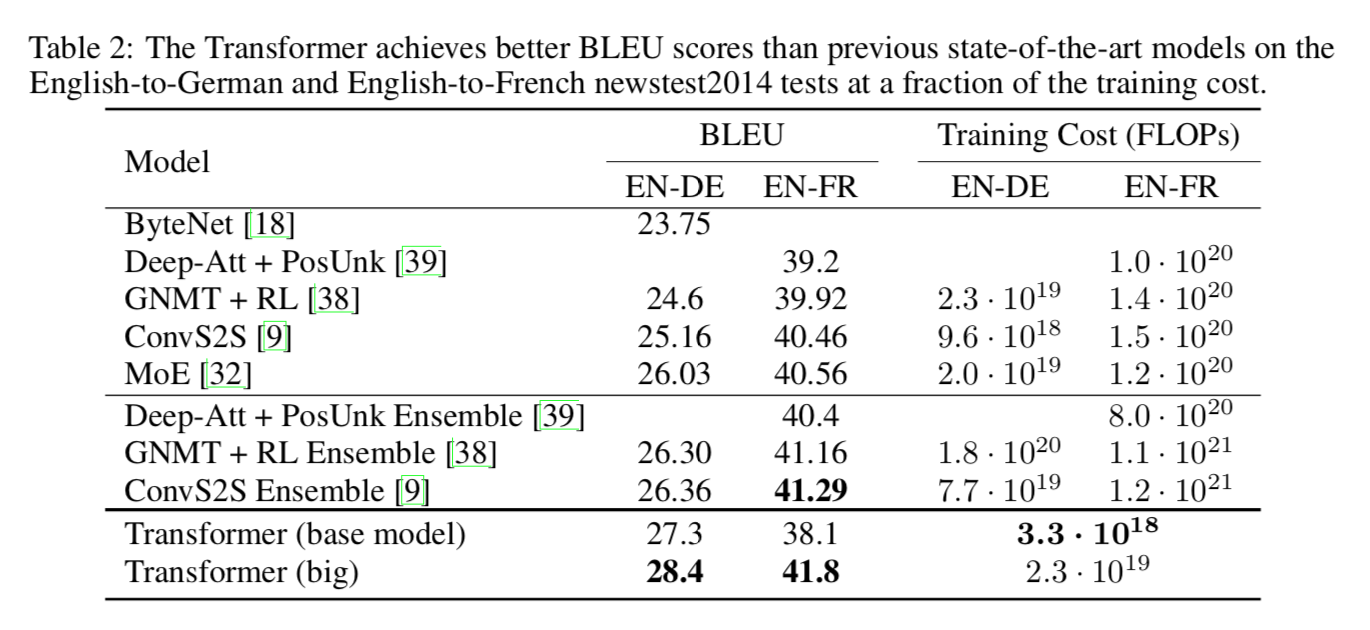
위에서 보이다싶이 MT에서도 SOTA 찍으면서 잘했고,

English Constituency Parsing에서도 잘했다. (WSJ = Wall Street Journal) 그래서 Model Variation을 보면,
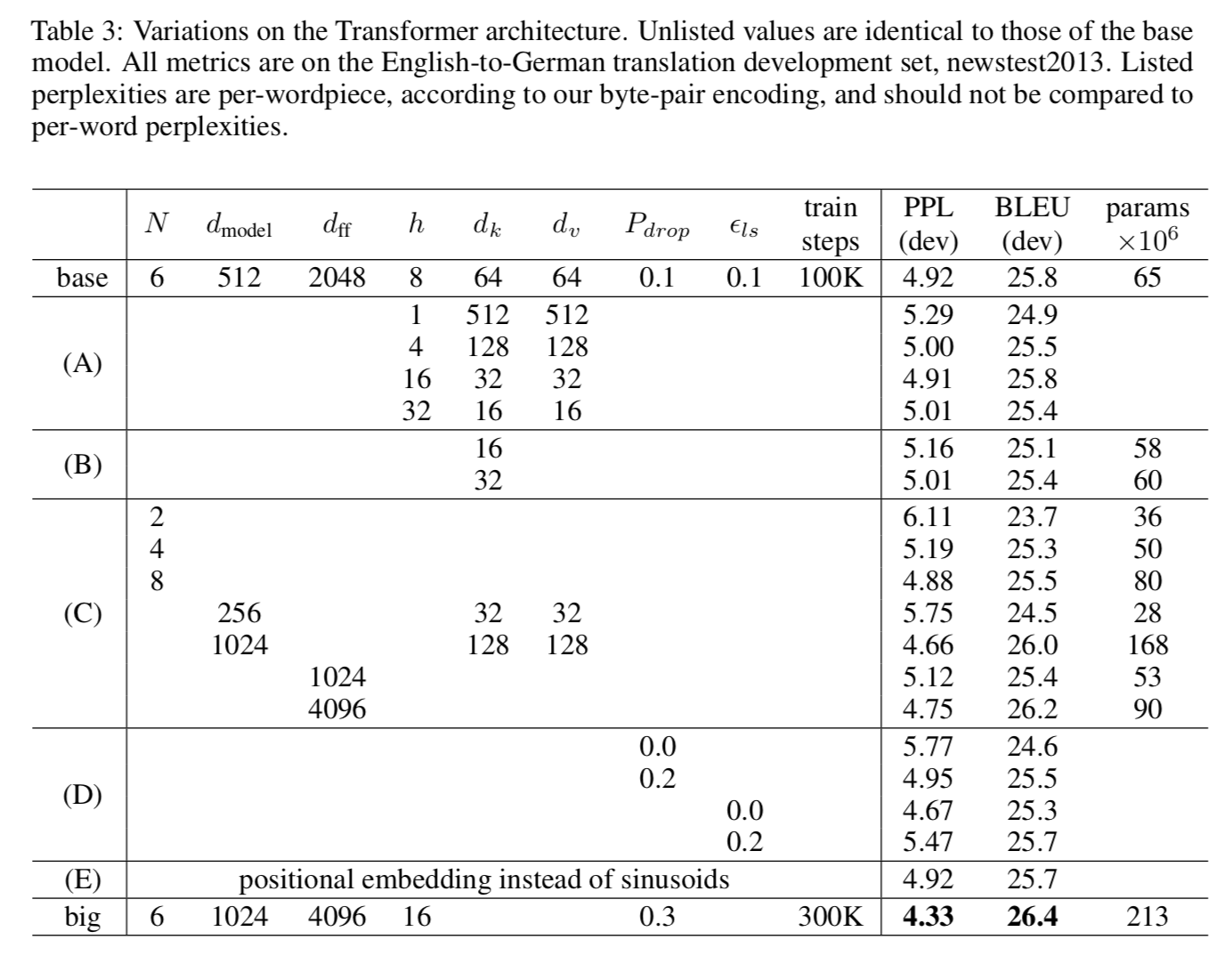
(A)에서는 attention heads와 attention key, value dimension을 다르게 하면서 테스트를 해보았고, (B)에서는 \(d_k\)만 줄였는데 이게 model quality를 안좋게만 했다고 한다. (C)랑 (D)에서는 dropout은 overfitting방지에 매우 좋고, 큰 모델이 그냥 잘하더라는… 결과이다. (E)에서는 sin함수 대신 learned positional embedding을 사용했는데, 그냥 거의 비슷하다고 한다.
7. Conclusion
이 논문에서 Transformer를 발표했고, fully attention base인, recurrent layer없는 것을 만들었다. 그래서 recurrent, convolution layer보다 훨씬 빠르게 학습이 가능하면서도 WMT 2014 English-to-German, WMT 2014 English-to-French translation task같은 곳에서 sota까지 달성했다.
다른 것에 attention-based model을 적용해보려 하는데, 일단 restricted attention을 image, audio, video같은 large input, output을 다루게 해보려고 한다고 한다.
transformer코드는 tensor2tensor를 참고하자.
-
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014. 를 참고하라고 하는데, 나중에 시간되면.. ↩
-
Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859, 2016.과 비슷한 방식 ↩
-
Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016.은 뭔지 모르겠으니까 다음에 간단하게 보자 ↩