최근 읽은 논문/아티클 정리 (PRADO, Quasi-RNN, Advancing NLP with Efficient Projection-Based Model Architectures, Small and Practical BERT Models for Sequence Labeling)
PRADO, Quasi-RNN, Advancing NLP with Efficient Projection-Based Model Architectures, Small and Practical BERT Models for Sequence Labeling 논문 정리입니다.
PRADO: Projection Attention Networks for Document Classification On-Device
- EMNLP-IJCNLP, 2019
- 모델 크기도 작은데 (~200KB) CNN, LSTM보다 좋은 성능을 낸다.
- 우선 long text classification을 풀기 위함인 듯 함.
- 현재까지는 통계학적 방법 + LSTM/CNN 활용등이 있었고, 최근에는 SGNN(self governing neural network)이나 SGNN++같은게 있었다. ((Ravi and Kozareva, 2018, 2019), (Ravi, 2017, 2019))
- 이 논문의 main contribution; long text classification용으로 on-device projection attention neural network; CNN, LSTM이나 기존의 feature engineering 방법 다 이김; Quantization 적용할 시 200KB정도 모델; robust하고 성능 향상의 여지가 더 있음
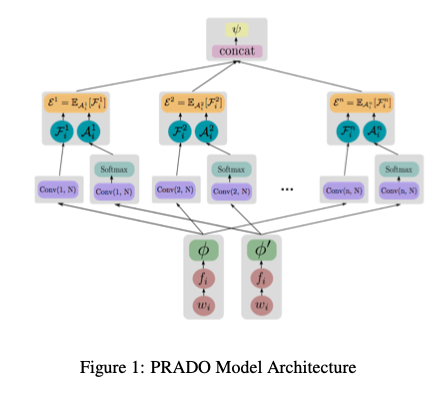
- Projected Embedding Layer + Convolution/Attention Encoder + Final Classifier Layer로 이루어져있다.
- Projected Embedding Layer
- 원래의 embedding layer는 모델 파라미터에서 차지하는 비율이 되게 높다. (이게 BERT 기준으로는 20%인데, 다른 작은 모델들은 더..)
- word vector를 이렇게 얻는다. \(e_i = \phi(f_i)\). \(f_i\)는 projection operator를 통해 \(w_i\)로부터 얻은 feature를 말하는 듯 하다.
- 이거 자세한 내용은 SGNN, SGNN++를 읽어야 할 듯..
- projection operator
- 우선 B bit feature를 뽑아내는 함수
- token \(w_i\)를 hash function으로 2B bit로 만든다.
- projection operator는 각 2bit를
{-1, 0, 1}을 mapping한다. - \(\phi\)는 일반적인 dense인듯..?
- Convolution & Attention
- 대부분의 단어가 Classification과 관련없고, min/max pool은 backprop을 어렵게 만든다.
- 그림을 보면 2개의 Convolution Layer가 보이는데, 1개는 그냥 Convolution하고, 다른 하나는 Convolution한 후 Softmax를 취했다고 한다. 그리고 그 두개를 가중합한다.
- n-gram kernel을 여러개 사용했는데, 거기다가 masked convolution kernel을 사용했다고 한다.
- 기존 bi-gram kernel이
[1, 1]이라고 하면 Skip 1 bi-gram은[1, 0, 1]이고 Skip 2 bi-gram은[1, 0, 0, 1]인 셈
- 기존 bi-gram kernel이
- 그렇게 해서 각 커널이 fixed length encoding을 하나씩 만들어 낸다.
- 최종 feature는 위에서 커널들이 만든 feature의 concat
- Classification Layer
- Concat된 것을 Dense 연산 하나 했고, 거기다가 CE Loss 사용함
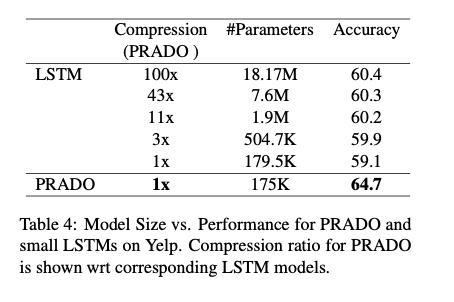
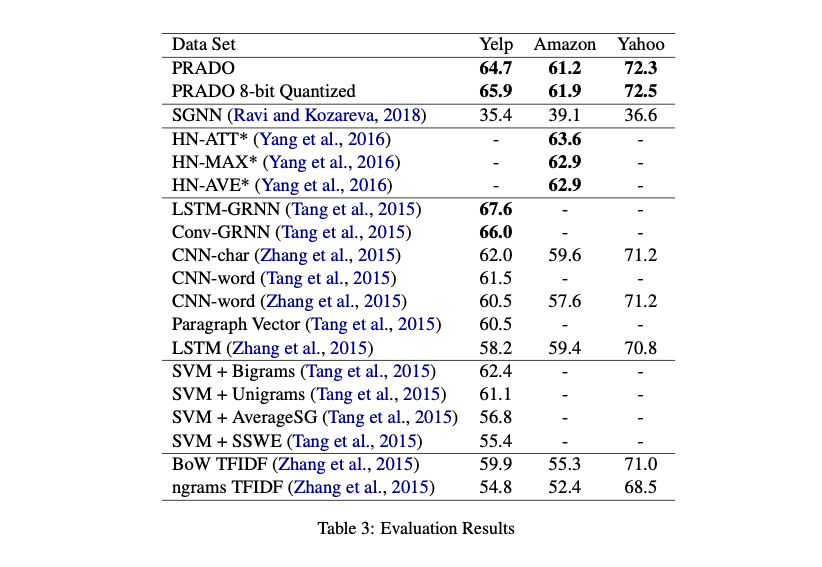
- 기존 CNN, LSTM 기반 모델들보단 잘하고, 같은 크기의 LSTM에 비해서는 월등함
- 물론 BERT같은 큰 모델과 비교하는 것은 무리고, GRNN에 비해서도 떨어지는 모습을 보임
- 하지만 같은 모델 사이즈에 비해서 정말 월등하다.
- Transfer Learning도 좋게 함
실제 String 처리 부분은 tensorflow/models/research/sequence_projection/tf_ops/sequence_string_projection_op_v2.cc여기보면 되겠다! Hash하는 부분은 tensorflow/models - commit 1611a8c5865ae1bccc22b71172b845bbc274ad00 research/sequence_projection/tf_ops/projection_util.h#L37-L134.
Quasi-Recurrent Neural Networks
- ICLR 2017
- 얘는 GitHub - jeongukjae/quasi-rnn 여기 간단하게 구현해보았다.
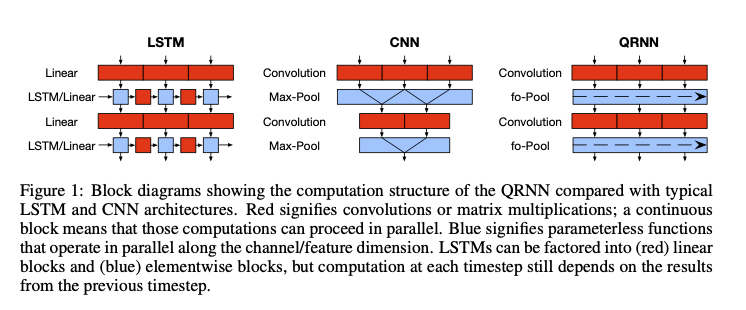
- CNN + Pooling이 기본
- CNN
- 각 kernel size \(k\)인 filter는 \(x_{t - k + 1}\) ~ \(x_t\)까지 참고함
- masked convolution(van den Oord et al., 2016)기법으로도 알려진 위 기법은 padding을 input 왼쪽에 filter size - 1만큼 적용해서 구현함
- 구현은 아래처럼 (\(*\)는 masked convolution)
- 기본 연산: \(Z = \tanh(W_z * X), F = \sigma(W_f * X), O = \sigma(W_o * X)\)
- pooling potions
- dynamic average pooling (simplest): \(h_t = f_t \odot h_{t- 1} + (1 - f_t) \odot z_t\)
- using output gate: \(c_t = f_t \odot c_{t- 1} + (1 - f_t) \odot z_t, h_t = o_t \odot c_t\)
- including independent input and forget gate: \(c_t = f_t \odot c_{t - 1} + i_t \odot z_t, h_t = o_t \odot c_t\)
- 각각 f-pooling, fo-pooling, ifo-pooling이라고 부른다.
- 처음에는 h, c를 zero로 씀
- 잘 구현하면 recurrent 한 부분은 계산량을 무시할만하다고 함 -> 기존 LSTM, GRU보다는 병렬화 잘 될 것 같다.
- Variants
- Regularization: dropout을 줄 수 있다. \(F = 1 - \text{dropout} (1 - \sigma(W_f * X))\)
- Densely-Connected Layers
- 기존의 Convolution을 잘 만들기 위한 기법을 적용가능
- dense convolution by Huang et al. (2016)
- Encoder–Decoder Models: 아래 모델처럼 만든대요

- 결과는 똑같이 쌓았을 때 Imdb Sentiment Classification에서 LSTm보다 좋고, 빠르다고 한다.
- 그리고 비슷한 사이즈의 LSTM보다 LM에서 PPL이 더 떨어진다.
- 속도는 빠르다고는 하는데, 실제로 최적화 하기에 따라 다를 듯..?
Advancing NLP with Efficient Projection-Based Model Architectures
위 두 논문을 결합해서 만들어보았더니 잘 되더라.. 정도인데, “civil_comments에서 BERT보다 300배 작은 모델이지만, 비슷한 성능을 내었다!!”정도로 요약가능하다.
PRADO에서 사용한 projection만 들고와서 bottleneck layer (dense bottleneck layer니까 hidden size 한번 줄였다가 다시 복구시켜주는 layer인 듯 하다) 쌓고, Bidriectional로 QRNN을 N 층 쌓았다고 한다. 이거 진짜 on-device에서 좋을 듯 하다.
Small and Practical BERT Models for Sequence Labeling
- EMNLP 2019
- public multilingual BERT checkpoint에서 시작해서 마지막엔 6배 작고 27배 빠르면서 정확도는 multilingual baseline 보다 높은 모델을 얻었다.
- single CPU에서 돌릴 수 있다.
- 3-layer BERT를 Teacher에 대해 Unlabeled Corpus로 Distillation을 하고, student모델을 labeled data에 대해 조금 더 finetuning을 함
- Sequence Labeling 문제이기 때문에 일반 Unlabeld Corpus에서는 Teacher Logit을 답으로 이용
- 추론 속도가 얼마나 나오는지는 나와있지 않은데, BERT가 Xeon CPU에서 230ms가 걸렸고 27배 빠르다고 하니까 대략 8.5ms 정도 걸린 것 같다.
October 13, 2020
Tags:
paper