최근 읽은 논문 정리 (AIN, Repulsive Attention, Improving Transformer Optimization Through Better Initialization, ReZero)
AIN, Repulsive Attention, Improving Transformer Optimization Through Better Initialization, ReZero 논문 정리입니다.
AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
- EMNLP 2020
- CRF는 sequential computation이 존재하기 때문에 parallelization이 힘들다.
- Sequence Labeling 문제(NER, POS Tagging)에서 BiLSTM - CRF가 가장 좋은 모델이라 알려져있다.
- CRF에 대해서는 Lafferty et al., 2001를 참고가능할 듯
- 여기서 속도를 향상하는 방법은 아래정도
- BiLSTM을 CNN으로 교체 (Strubell et al., 2017)
- Encoder에 해당하는 Embedding - BiLSTM을 작은 모델로 Distillation (Tsai et al., 2019)
- 하지만 위 두 방법 모두 CRF를 교체한 것이 아니라 다른 모델 부분을 교체한 것인데, 정작 병목은 CRF에도 있기 떄문에 CRF를 교체
- Mean-Field Variational Inference (MFVI)를 적용해서 linear chain CRF를 교체
- binary feature를 사용하는 CRF를 transition score만을 저장하는 matrix하나와 input sentence의 contextual representation의 matmul 결과 값을 쓴다.
- CRF와 비슷한 성능을 보이면서 BiLSTM, 128 words 길이에서 4배 이상빠른 속도를 보여준다.
Repulsive Attention: Rethinking Multi-head Attention as Bayesian Inference
- MHA가 attention collapse라는 문제를 상당히 많이 겪는다.
- 서로 다른 head가 같은 feature만을 잡으려는 현상이고 이게 모델 capacity에 비해 안좋은 성능의 원인이 된다.
- 그래서 이 논문에서는 Bayesian 관점에서 MHA를 분석한다. 그리고 particle-optimization sampling technique을 사용하여 MHA의 성능을 향상시키는 방법을 제시한다.
- 자세한 원리는 잘 모르겠지만, 이 논문의 핵심은 아래 정도로 보인다.
- NLL Loss를 예시로 들면 gradient가 어느정도 uniform하게 나올 것이다. 그래서 Head를 아래와 같은 식으로 업데이트한다.

- approximation error가 있을 수 있다고 하니까 이건 주의하자 (Zhang et al., 2018)
- 대신 큰 데이터셋에서 잘되는데 성능은 확실히 오른다.
Improving Transformer Optimization Through Better Initialization
- ICML 2020
- 목적
- learning rate warmup이 없을 때 Transformer 학습이 왜 실패하냐
- weight initialization으로 layer normalization과 warmup을 없애본다.
- 그래서 깊은 Transformer도 학습 가능
- 이전 연구들과 함께 종합해서 layer normalization이 학습에 영향을 끼친다는 사실을 보여주겠다.
- 그리고 Xiong et al. (2020)이 말했던 것처럼 gradient가 explode하는게 아니라 gradient는 낮은 레이어에서 (특히 임베딩에서) vanishing된다.ㅁ
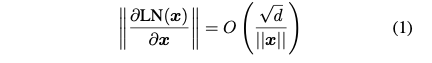
- 위 식처럼 Layer Normalization을 지나갈 때 input norm이 크다면 Graident는 Down Scale된다. 그래서 레이어를 깊게 쌓으면 학습을 못하는 것이다.
- Liu et al. (2020)에서는 adaptive stochastic optimization algorithm들은 초반에 variance에 대해서도 optimize하는데 이게 문제가될 수 있다고 한다. -> 여기서 RAdam이 나옴
- 그래서 아래처럼 된다. a, b는 학습 후인데 반해 c, d는 warmup을 없앨 경우에 이렇게 완전 gradient가 vanishing된다..를 보여주는 것이다. e, f는 fixup을 사용하는 경우이다.
- 조금 더 해석해보자면, c, d는 iteration을 돌면서 계속해서 gradient가 없어지는 반면, a, b 처럼 학습이 잘 되어 있는 모델은 gradient가 일정하다. 하지만 T-Fixup은 그냥 gradient가 저렇게 일정하다고 한다.

- 추가로 SGD로 학습을 해보았는데, warmup이 없을 경우에는 오히려 초반에는 Adam보다 잘한다고 한다. (초반에 Adam이 불안정하긴 한가보다)
- 그 이유를 살펴보면 Liu et al. (2020)에서 말하기로 Adam은 moving average를 gradient의 second moment를 게사하기 위해 사용하는데 이게 unbounded라서 위험하다고 한다.
- 초반에는 몇개 안되는 샘플에서 뽑힌 것이라 초반에 불안정하다고 한다.
- Decoder도 있는 상황에 대해 Initialize하는 거라서 Encoder only(BERT 같은)에도 적용할 수 있을까 싶은데 잘 모르겠다. 그래도 이 논문의 메인 목표는 encoder-attention이긴 하다.
- input embedding을 빼고는 Xavier initialization을 써라. input embedding에 대해서는 Gaussian initialization (stddev가 \(d^{-\frac 1 2}\))을 써라.
- 아래를 \((9N)^{- \frac 1 4}\)로 scale해라
- 각 decoder attention 블럭의 \(v_d\), \(w_d\) (output projection)
- decoder MLP block의 weight matrix
- encoder, decoder 블럭의 input embeddings x, y
- 각 encoder block의 \(v_e\)와 \(w_e\)(output projection)와 encoder MLP BLock의 weight를 \(0.67N^{- \frac 1 4}\)로 scale해라
- 그리고 layer normalization을 없앴다고 한다.
- 근데 생각보다 깊은 transformer에서 잘한다.
- Fixup Initialization: Residual Learning Without Normalization을 같이 보면 좋을 것 같다. 나중에 읽어야지
ReZero is All You Need: Fast Convergence at Large Depth
- 아직 under review
- 논문의 핵심 아이디어는 norm빼고 residual connection에서 learnable parameter(scalar 값)을 하나 곱해주는 것.
- \[x_{i + 1} = x_i + \alpha_i F(x_i)\]
- 관심있는 부분은 Transformer 였는데, 생각보다 잘 된다. -> 리뷰한 논문들 중 몇 안되게 구현해서 돌려본 모델
September 25, 2020
Tags:
paper